
Ai00 Inference
Introduction
The Ai00 Server is an inference API server for the RWKV language model, based on the web-rwkv inference engine. It is also an open-source software licensed under the MIT license, developed by the Ai00-x development team led by members of the RWKV open-source community, @cryscan and @顾真牛.
The Ai00 Server supports Vulkan as the inference backend and enables Vulkan parallel and concurrent batch inference. It can run on all GPUs that support Vulkan. In fact, the Ai00 Server is compatible with most NVIDIA, AMD, and Intel graphics cards (including integrated graphics cards).
While offering high compatibility, the Ai00 Server does not require bulky environments like PyTorch, CUDA, and other runtimes. It has a compact structure, is ready to use out of the box, and supports INT8/NF4 quantization, allowing it to run at high speed on most personal computers.
The repository address of the Ai00 Server: https://github.com/Ai00-X/ai00_server
This beginner's tutorial aims to provide guidance for those who are new to the RWKV large model and the Ai00 Server. By following the steps in this article, you should be able to successfully run the RWKV model locally using the Ai00 Server and perform various tasks, including chatting, text generation, translation, and question answering.
Simple Usage
Download and Installation
For beginners, we recommend directly downloading the latest version from the Release page of the Ai00 Server.
In the Assets section of each release, you can find the packaged compressed file of the Ai00 Server. Just download and unzip it to start using it.
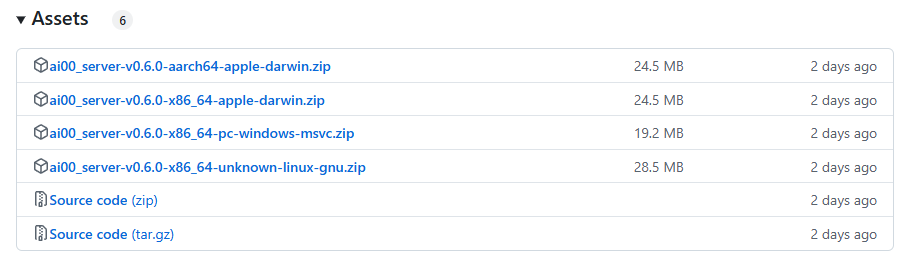
aarch64-apple-darwin: Suitable for macOS systems with Apple M-series chipsx86_64-apple-darwin: Suitable for macOS systems with Intel chipsx86_64-pc-windows-msvc: Suitable for Windows 64-bit systemsx86_64-unknown-linux-gnu: Suitable for Linux 64-bit systems
VRAM Requirements of Ai00
The following are the VRAM requirements for different quantization methods of Ai00:
Tips
Test environment:
- CPU: i7-10870H
- GPU: RTX 4090, 24G VRAM
- Memory: 32GB
| Quantization Method | 1B6 Model | 3B Model | 7B Model | 14B Model |
|---|---|---|---|---|
| FP16 | 3.2GB VRAM | 6.5GB VRAM | 14.4GB VRAM | Approximately 29G VRAM |
| INT8 | 2GB VRAM | 4.4GB VRAM | 8.2GB VRAM | 14.8GB VRAM |
| NF4 | 1.3GB VRAM | 2.6GB VRAM | 5.2GB VRAM | 10.4GB VRAM |
Warning
All layers are quantized by default. The higher the number of quantized layers, the lower the VRAM usage, but the performance of the model may deteriorate.
Download/Convert RWKV Model
The Ai00 Server currently only supports Safetensors models with the .st file extension. There are two ways to obtain a .st model.
Tips
If you don't have any model weights locally, it is recommended to directly download the .st model from the repository. If you already have a .pth file locally, you can convert the .pth file to a .st file according to the following conversion tutorial.
Download the already converted .st model from the following repositories:
- RWKV-7 ModelScope Repository (Recommended)
- RWKV-6 ModelScope Repository
First, go to the Python official website to download and install Python, and then use pip to install the required libraries:
pip install numpy torch safetensors
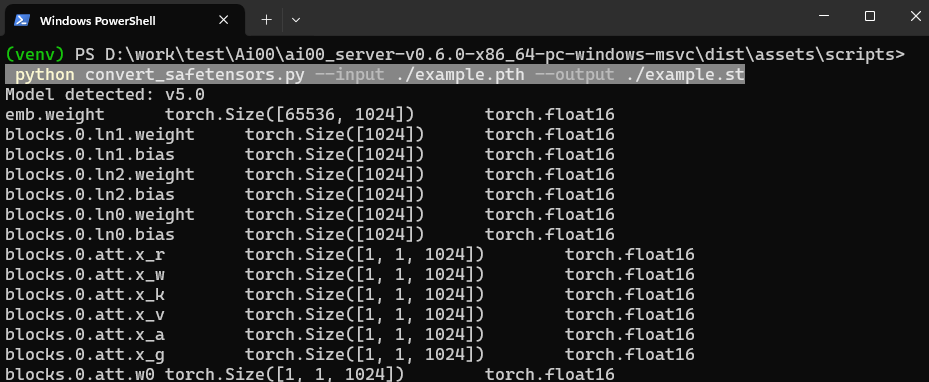
Then move the .pth file to the dist/assets/scripts directory. Start the terminal and execute the following command to convert the specified .pth model into a .st model:
python convert_safetensors.py --input ./model.pth --output ./model.st
Tips
Please change ./model.pth in the above command to the .pth model file that needs to be converted; At the same time, change ./model.st to the target .st model file.
The following is an example of a successful run. Note that you need to use the ./ relative path, otherwise some systems cannot directly read the current file path.
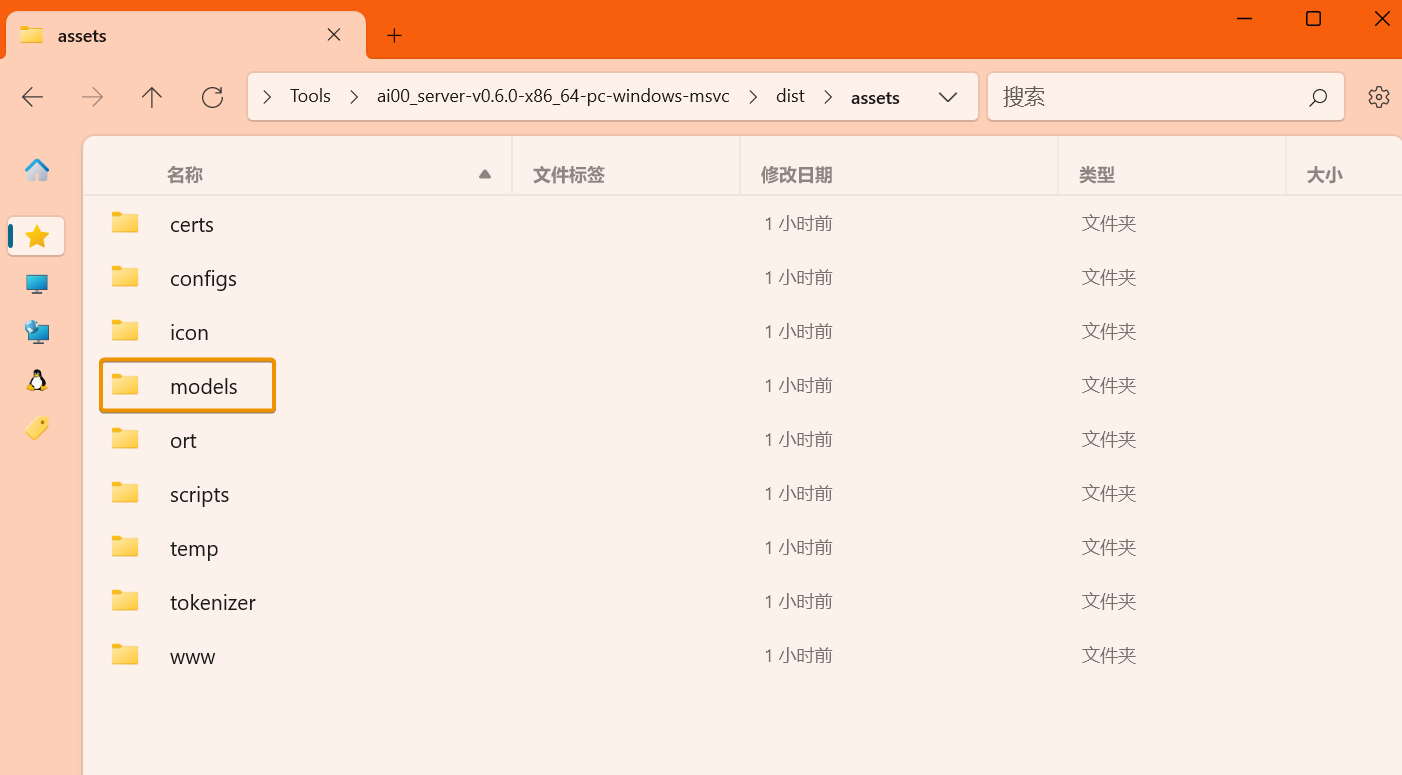
After obtaining the RWKV model with the .st file extension, create a new models folder in the dist/assets directory of Ai00 and place the RWKV model in this folder.
Adjust Configuration Parameters
The Ai00 program will run the RWKV model according to the parameters in the assets/configs/Config.toml configuration file. You can modify the configuration items in Config.toml through a text editing software (such as Notepad) to adjust the running effect of the model.
The following is a sample Config.toml configuration.
[model]
embed_device = "Cpu" # Place the Embed matrix of the model on the GPU or CPU
max_batch = 8 # [It is not recommended to change] The maximum batch cached on the GPU
name = "RWKV-x060-World-3B-v2.1-20240417-ctx4096.st" # Model name, only supports models in the .st format. Please download the converted model or convert it yourself
path = "assets/models" # The path where the model is stored
precision = "Fp16" # [It is not recommended to change] Intermediate tensor precision ("Fp16" or "Fp32"). Fp32 has higher precision but is slower
quant = 0 # The number of quantized layers. Increasing it will improve efficiency, but it may reduce precision and deteriorate the model's performance
quant_type = "Int8" # Quantization type ("Int8" or "NF4"). Int 8 has better performance than NF4 but requires more VRAM
stop = ["\n\n"] # [It is not recommended to change] Add additional generation stop words
token_chunk_size = 128 # Parallel Token block size, ranging from 32-128. The more powerful the graphics card, the larger this number can be adjusted (64 or 128)
# [[state]] # Whether to mount the state file
# id = "fd7a60ed-7807-449f-8256-bccae3246222" # The UUID of the state file. If not specified, it will be randomly assigned
# name = "x060-3B" # Whether to name this state file (optional), can be filled with null
# path = "rwkv-x060-chn_single_round_qa-3B-20240505-ctx1024.state" # The path of the state file. If it is stored in the assets/models directory, you can fill in the file name
# [[state]] # Continue to mount multiple state files
# id = "6a9c60a4-0f4c-40b1-a31f-987f73e20315" # The UUID of the state file. If not specified, it will be randomly assigned
# name = "x060-7B" # Whether to name this state file (optional), can be filled with null
# path = "rwkv-x060-chn_single_round_qa-3B-20240502-ctx1024.state" # The path of the second state file. If it is stored in the assets/models directory, you can fill in the file name
# [[lora]] # Whether to mount the LoRA file by default
# alpha = 192 # The alpha value of the LoRA file
# path = "assets/models/rwkv-x060-3b.lora" # The path of the LoRA file
[tokenizer]
path = "assets/tokenizer/rwkv_vocab_v20230424.json" # [It is not recommended to change] The path of the tokenizer
[bnf]
enable_bytes_cache = true # [It is not recommended to change] Whether to enable the cache mechanism to accelerate the expansion process of some short patterns (schemas) in BNF.
start_nonterminal = "start" # [It is not recommended to change] Specify the initial non-terminal symbol in the BNF pattern.
[adapter]
Auto = {} # [It is not recommended to change] Automatically select the best GPU.
# Manual = 0 # Manually specify which GPU to use. You can obtain the list of available GPUs through the API (get) http://localhost:65530/api/adapters
[listen]
acme = false # [It is not recommended to change] Whether to enable the acme certificate
domain = "local" # [It is not recommended to change] The domain name of the Ai00 service
ip = "0.0.0.0" # IPv4 address
# ip = "::" # Use IPv6
force_pass = true # Whether to force through the authentication step. Change it to false to use key authentication to control the access rights of the admin series of APIs
port = 65530 # The port of the Ai00 service
slot = "permisionkey"
tls = false # Whether to use https. If you are only experiencing AI00 locally, it is recommended to set it to false
[[listen.app_keys]] # Add multiple keys for administrator authentication
app_id = "admin"
secret_key = "ai00_is_good"
[web] # [It is not recommended to change] Remove this item to disable the WebUI
path = "assets/www/index.zip" # [It is not recommended to change] The path of the web interface resources
# [It is not recommended to change] Enable a third-party embedding model (using the fast-embedding onnx model)
# You can use the API (post) http://localhost:65530/api/oai/embeds to call the third-party embedding model for embedding operations
# [embed] # Uncomment [embed] and the following to enable the third-party embedding model
# endpoint = "https://hf-mirror.com" # The source of the third-party embedding model
# home = "assets/models/hf" # The storage path of the third-party embedding model
# lib = "assets/ort/onnxruntime.dll" # Only used in Windows
# name = { MultilingualE5Small = {} } # The name of the third-party embedding model
Run the Ai00 Program
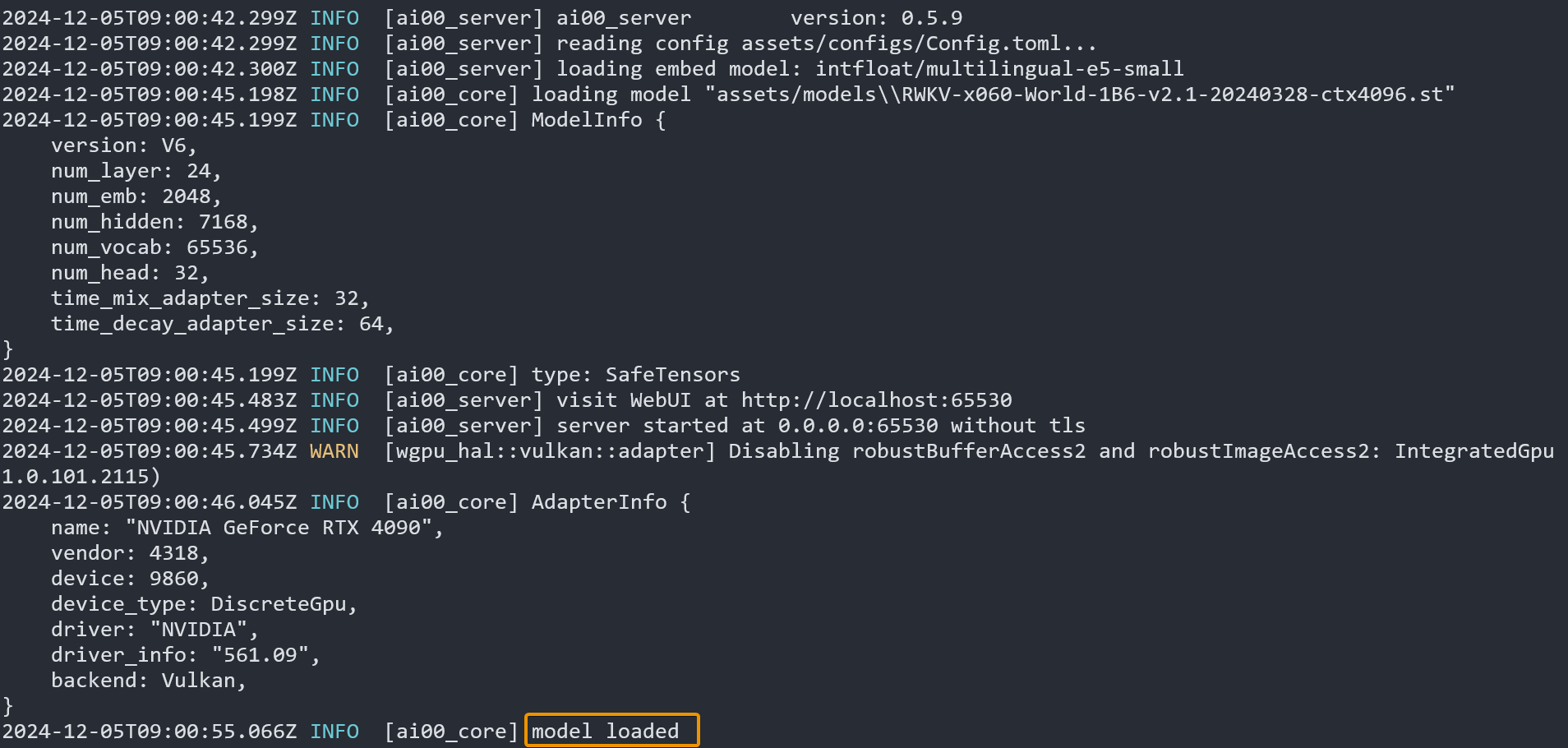
After modifying the configuration items, save the Config.toml file and double-click to run the ai00_server.exe program.
When the prompt INFO [ai00_server::middleware] model loaded appears in the command line, it means that the model has been loaded successfully:
At this time, open any browser and visit http://localhost:65530 to open the Ai00 Web interface.
Warning
If you set tls = true in the config file, please visit https://localhost:65530.
Adjust the Decoding Parameter
There are some model decoding parameters that can be set on the right side of the Web page, such as Temperature, Top_P, Presence Penalty, and Frequency Penalty. Adjusting these parameters will affect the generation results of the model.
The effects corresponding to the parameters are as follows:
| Parameter | Effect |
|---|---|
Top_P | Select the top |
Temperature | The temperature parameter |
Presence penalty | Presence penalty applies a fixed penalty to all tokens that have appeared, thereby increasing the possibility of the model generating new tokens. |
Frequency Penalty | Frequency penalty applies an accumulative penalty based on the number of times a token appears, thereby reducing the possibility of the model frequently repeating the same content. |
max_tokens | The maximum number of tokens when the model generates text, which can be understood as "the maximum number of characters the model can generate at one time". |
Tips
For a more detailed explanation of the decoding parameters and parameter recommendations, refer to RWKV's Decoding Parameters.
Advanced Features
description: The Ai00 Server is an inference API server for the RWKV model. It can run on all GPUs that support Vulkan and is compatible with most graphics cards from NVIDIA, AMD, and Intel (including integrated graphics cards). keywords: Ai00 State, How to Mount a State, How to Mount a LoRA in Ai00, How to Use a State File
In addition to driving the RWKV model for conversations and text continuation, Ai00 has many advanced features, such as mounting State files, LoRA files, and using BNF.
You can return to this page when a new version of Ai00 is released to view the latest features of Ai00.
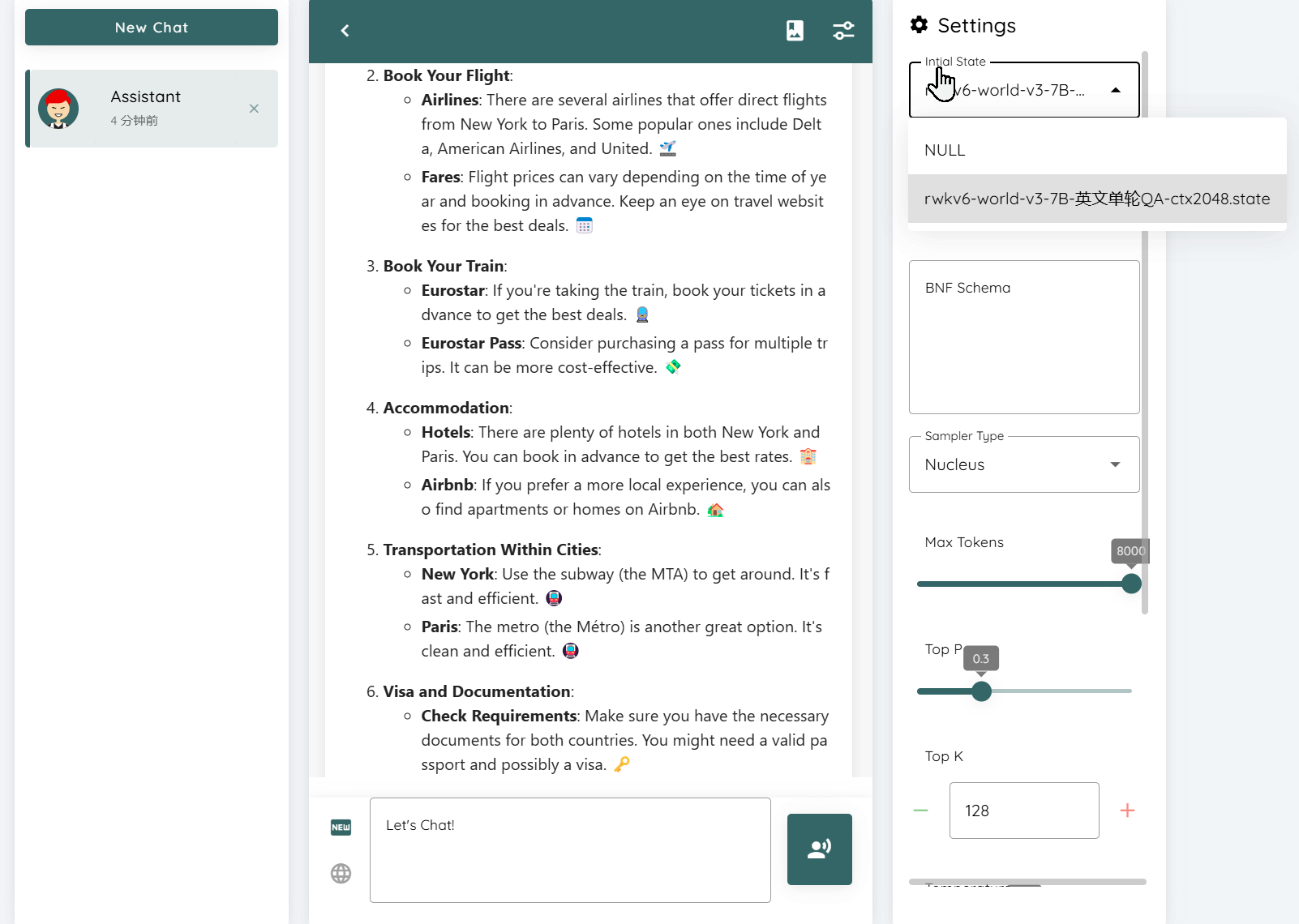
Mount a State File [Version 0.4.9]
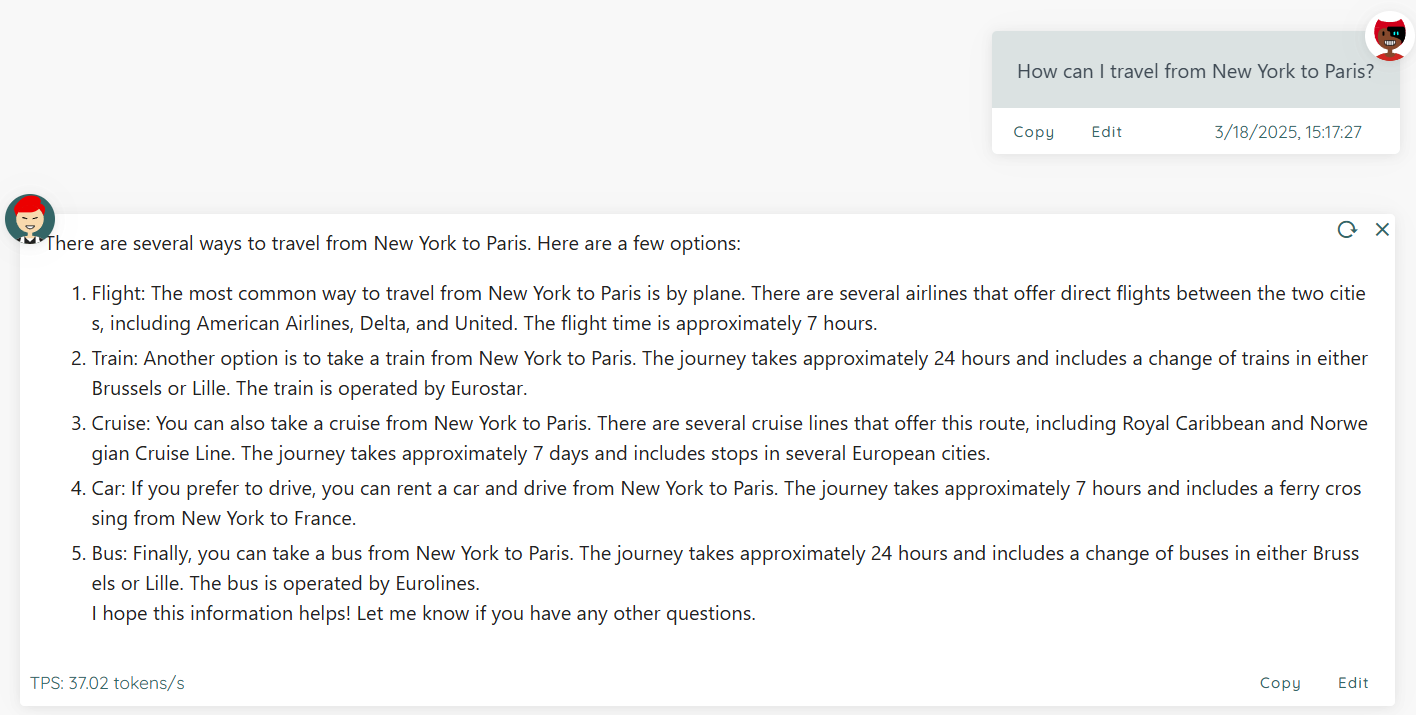
Mounting a State file can enhance the model's performance on a specific type of task. Taking a State that enhances single-round Q&A + emoji as an example, for the same question "How to get from Tokyo to Paris", the style of the model's answers before and after mounting the State is completely different:
Without mounting a State file:
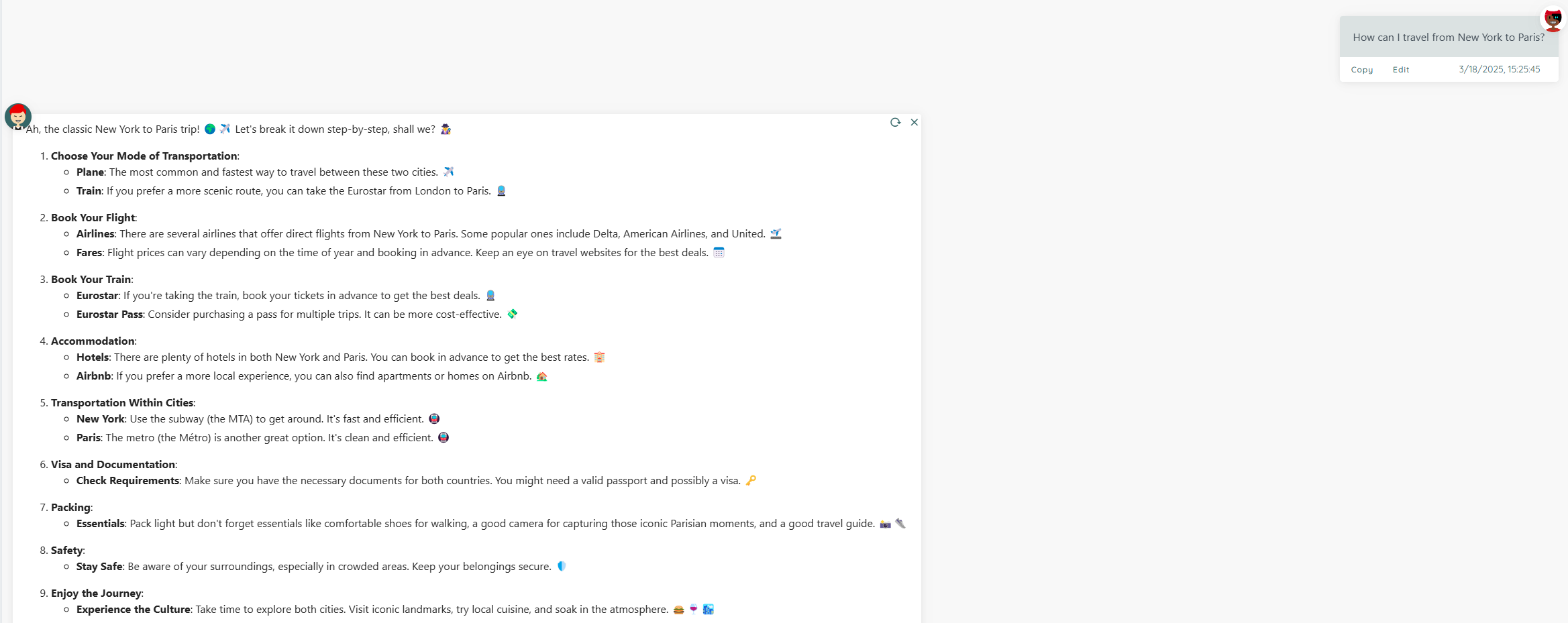
After mounting the State file for "Enhanced Single-Round English Conversation + Emoji":
Download a State File
The Ai00 Server currently only supports State files with the .state extension. You can download .state files from the HF repository.
If you cannot access the above website, please visit the HF mirror site.
How to Mount a State File
Modify the parameters related to mounting a State in the Config.toml configuration file: Remove the # comment symbol and modify the corresponding parameters.
The reference configuration information is as follows:
[[state]] # Whether to mount a state
# id = "fd7a60ed-7807-449f-8256-bccae3246222" # Generally, do not specify the UUID in a non-development environment. You can keep the comment symbol.
name = "x060-7B-Chinese" # Name this state file "x060-7B-Chinese"
path = "rwkv-x060-chn_single_round_qa-7B-20240516-ctx2048.state" # The name of the state file, stored in the `model` folder
After starting the RWKV model, you can switch the State file in the upper right corner of the WebUI interface.
Precautions for Mounting a State File
Warning
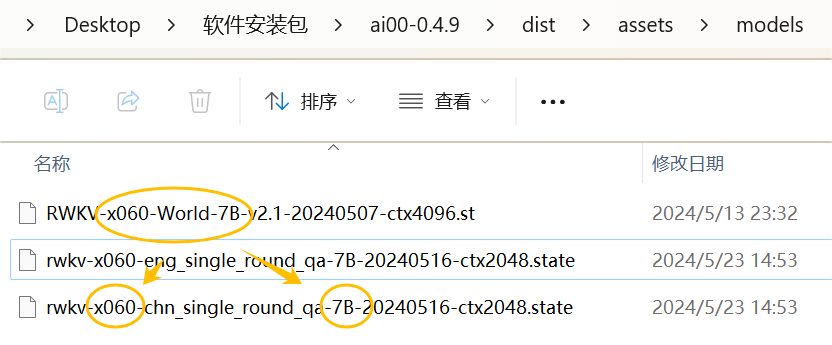
Note: When mounting a state file, you must use the base RWKV model with the same parameters as the State file.
For example, if this State file is fine-tuned based on the RWKV-6-World-7B model, then you must start the RWKV-6-World-7B model in Ai00 for the mounted State file to take effect.
Tips
As of version 0.5.0 of Ai00, it is supported to dynamically switch States in the upper right of the WebUI - Chat mode, but it is not supported to mount multiple States simultaneously.
Mount a LoRA Model [Version 0.4.9]
Mounting a LoRA model has a similar effect to mounting a State, which can also enhance the model's performance on a certain type of task.
How to Mount a LoRA Model?
You can modify the parameters for mounting a LoRA model in the Config.toml file configuration:
# [[lora]] # Whether to enable LoRA by default
# alpha = 192 # The larger the alpha value, the greater the influence of LoRA on the model output.
# path = "assets/models/rwkv-x060-3b.lora" # The path of the LoRA file
To enable the LoRA mounting function, remove the # comment symbol and modify the corresponding parameters. Refer to the following:
[[lora]] # Enable LoRA by default
# alpha = 192 # The larger the alpha value, the greater the influence of LoRA on the model output.
path = "assets/models/rwkv-x060-3b.lora" # The path of the LoRA file
Precautions for Mounting a LoRA File
Warning
Similar to mounting a state, when mounting a LoRA file, you must use the base RWKV model with the same parameters as the LoRA model.
For example, if this LoRA file is fine-tuned based on the RWKV-6-World-3B model, then you must start the RWKV-6-World-3B model in Ai00 for the mounted LoRA file to take effect.

Tips
As of version 0.5.0 of Ai00, it is supported to load multiple LoRAs simultaneously in the WebUI, but it is not supported to dynamically switch LoRAs in the WebUI.
This means that to cancel a LoRA, you must restart the Ai00 service.
BNF (Backus-Naur Form) [Version 0.4.9]
BNF can force the model to output in the format you want (for example, JSON, markdown with specified fields).
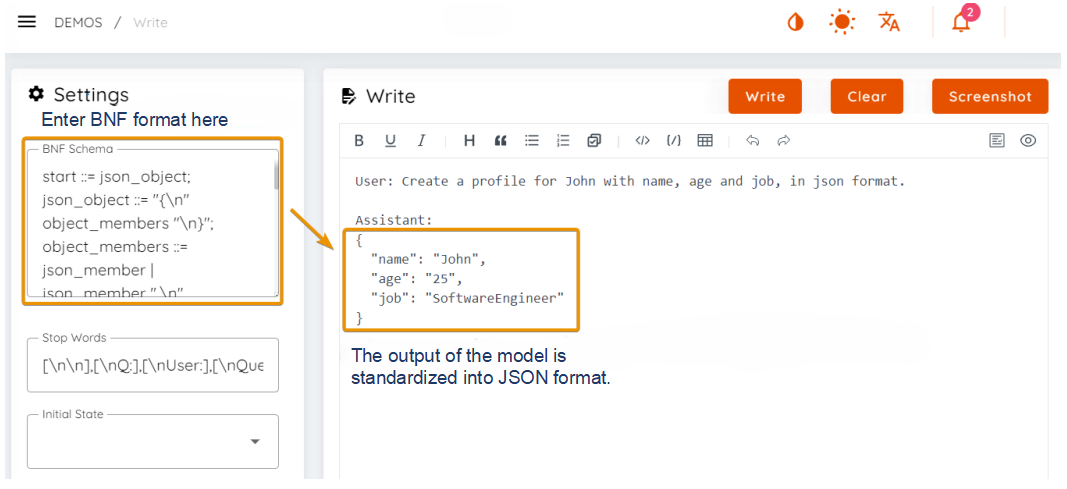
The following is an example of a JSON BNF that contains the fields name, age, and job:
start ::= json_object;
json_object ::= "{\n" object_members "\n}";
object_members ::= json_member | json_member ",\n" object_members;
json_member ::= "\t" json_key ": " json_value;
json_key ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"';
json_value ::= json_string | json_number;
json_string ::= '"'content'"';
content ::= #"\\w*";
json_number ::= positive_digit digits|'0';
digits ::= digit|digit digits;
digit ::= '0'|positive_digit;
positive_digit::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9";
Using this prompt, the model will output text in JSON format:
User: Create a profile for John with name, age and job, in json format.
Assistant:
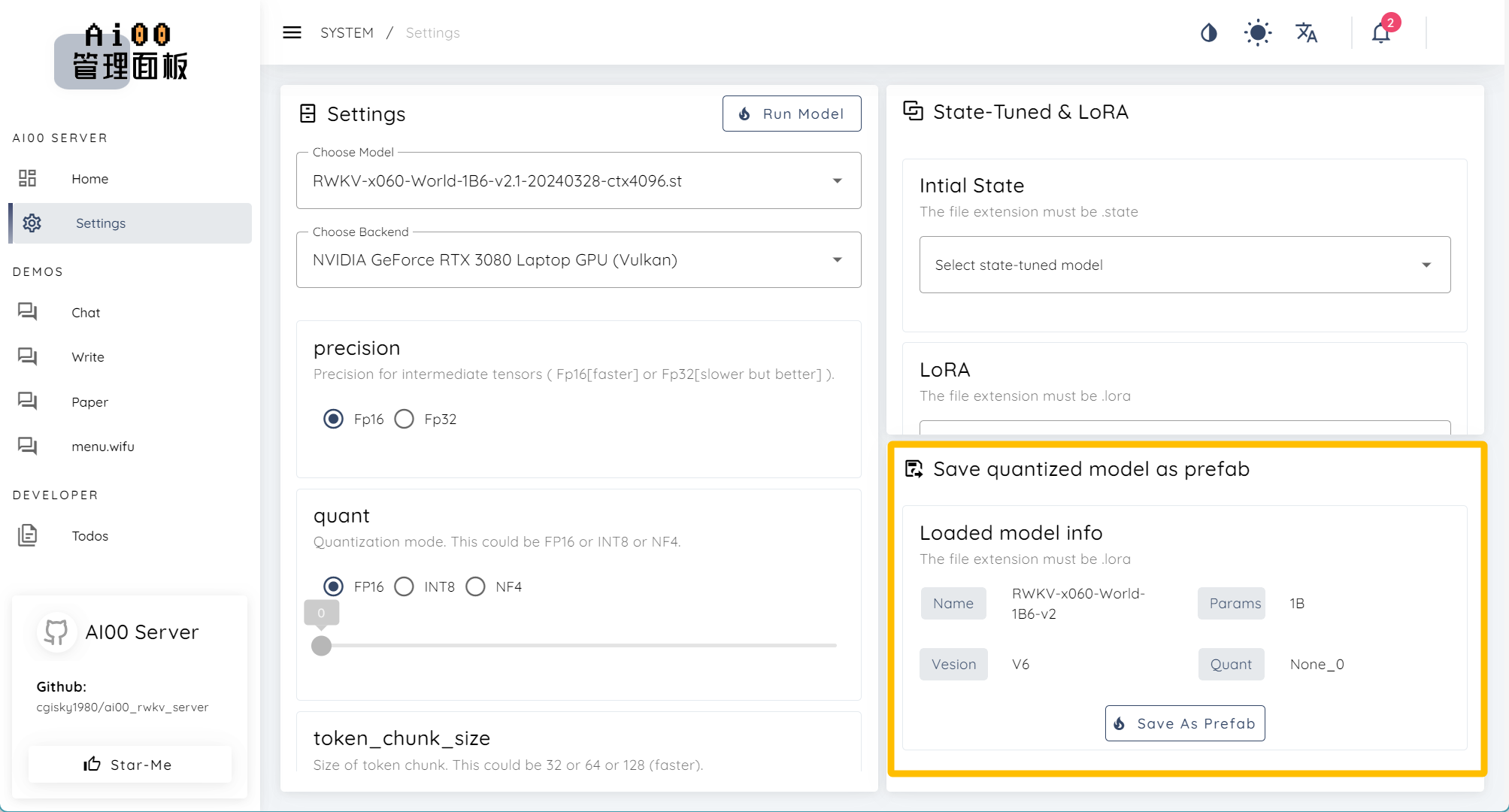
Use a Quantized Model in Prefab Format [Version 0.4.9]
Tips
What is the prefab format? What is the use of the RWKV model in prefab format?
The .prefab prefab usually refers to a resource format used in game development, which allows developers to create, save, and reuse the configurations of game objects (GameObjects) and their components.
Ai00 supports importing and exporting RWKV models in the .prefab format. This format can include the quantization type and the number of quantized layers, thereby saving the online quantization time when loading the RWKV model.
In the WebUI - Setting interface of Ai00, you can export the currently loaded RWKV model in the .prefab format, along with the quantization type and the number of quantized layers.
In the Config.toml configuration file, you can use the RWKV model in the .prefab format by modifying the model path parameter.
# [[model]]
path = "rwkv-x060-3b.prefab" # Specify the path of the RWKV model in prefab format
Tips
When using the RWKV model in the .prefab format, there is no need to specify the quantization type and the number of quantized layers. The model will automatically load the quantization information recorded in the prefab file.
API Documentation of Ai00
The following is the API documentation of Ai00, which contains detailed descriptions of all APIs.
After starting Ai00 locally, you can open the API documentation of Ai00 through http://localhost:65530/api-docs/.
api/oai/chat/completions
API Function: api/oai/chat/completions and api/oai/v1/chat/completions are the same API, which is used for the chat continuation mode of RWKV, that is, to have a conversation with the model.
API Address: (post) http://localhost:65530/api/oai/chat/completions
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| messages | Required | array<object> | Conversation history. Each object contains two fields: role (role) and content (content). |
| names | Required | object<Role, string> | Role name mapping. You can customize the display names of roles such as system/user/assistant/observation, etc. |
| state | Optional | string | Specify the UUID of the RWKV state file to be used. |
| max_tokens | Optional | integer | The maximum number of tokens for the generated text. |
| stop | Optional | array<string> | List of stop words. When the generated content contains these words, the generation will stop. The default value is ["\n\n"]. |
| stream | Optional | boolean | Whether to generate text in stream mode. The default value is false. |
| bias | Optional | object<number, number> | Mapping from token id to weight, used to adjust the generation probability of specific tokens. The default value is empty. |
| bnf_schema | Optional | string | null | BNF syntax rules, used to restrict the output format of the model. The default value is null. |
| sampler | Optional | object | Default sampling parameters (Nucleus type). |
| sampler_override | Optional | Option<SamplerParams> | Override the default sampling parameters and you can choose different sampling methods. |
Reference API Request Body
{
"max_tokens": 1000,
"messages": [
{
"content": "Hi!",
"role": "user"
},
{
"content": "Hello, I am your AI assistant. If you have any questions or instructions, please let me know!",
"role": "assistant"
},
{
"content": "Tell me about water.",
"role": "user"
}
],
"names": {
"assistant": "Assistant",
"user": "User"
},
"sampler_override": {
"frequency_penalty": 0.3,
"penalty": 400,
"penalty_decay": 0.99654026,
"presence_penalty": 0.3,
"temperature": 1,
"top_k": 128,
"top_p": 0.5,
"type": "Nucleus"
},
"state": "00000000-0000-0000-0000-000000000000",
"stop": [
"\n\nUser:"
],
"stream": false
}
Reference API Return Result
{
"object": "chat.completion",
"model": "assets/models\\RWKV-x060-World-1B6-v2.1-20240328-ctx4096.st",
"choices": [
{
"message": {
"role": "Assistant",
"content": "Water is a liquid that is essential for life on Earth. It is a mixture of hydrogen and oxygen atoms, which makes it a highly reactive and polar molecule. Water has a high surface tension and is able to form water droplets when it comes into contact with other substances. It is found in various forms, including ice, snow, rain, and fog. Water is also essential for the growth and survival of plants and animals."
},
"index": 0,
"finish_reason": "stop"
}
],
"usage": {
"prompt": 41,
"completion": 88,
"total": 129,
"duration": {
"secs": 4,
"nanos": 381959200
}
}
}
Explanation of the Return Result:
object: Type of the returned object, fixed as "chat.completion"model: Path of the currently used modelchoices: Array of generated results, containing the following fields:message: Generated message object, containing:role: Type of the role, fixed as "Assistant"content: Generated text content
index: Index number of the resultfinish_reason: Reason for the stop of generation
usage: Usage statistics information, containing the following fields:prompt: Number of tokens in the input promptcompletion: Number of tokens in the generated contenttotal: Total number of tokensduration: Generation time consumption, including seconds and nanoseconds
api/oai/completions
API Function: api/oai/completions and api/oai/v1/completions are the same continuation API, which is used for the basic continuation mode to let the model continue to generate content following your prompt.
API Address: (post) http://localhost:65530/api/oai/completions
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| prompt | Required | Array<String> | Array of continuation prompt texts you provide to the model. |
| state | Optional | string | Specify the UUID of the RWKV state file to be used. |
| max_tokens | Optional | integer | The maximum number of tokens for the generated text. The default value is 256. |
| stop | Optional | Array<String> | List of stop words. When the generated content contains these words, the generation will stop. The default value is ["\n\n"]. |
| stream | Optional | boolean | Whether to generate text in stream mode. The default value is false. |
| bias | Optional | HashMap<u16, f32> | Mapping from token id to weight, used to adjust the generation probability of specific tokens. The default value is empty. |
| bnf_schema | Optional | Option<String> | BNF syntax rules, used to restrict the output format of the model. The default value is None. |
| sampler | Optional | NucleusParams | Default Nucleus sampling parameters. |
| sampler_override | Optional | Option<SamplerParams> | Override the default sampling parameters and you can choose different sampling methods. |
Reference Request Body:
{
"prompt": [
"The Eiffel Tower is located in the city of"
],
"stop": [
"\n\n",
"."
],
"stream": false,
"max_tokens": 1000,
"sampler_override": {
"type": "Nucleus",
"top_p": 0.5,
"top_k": 128,
"temperature": 1,
"presence_penalty": 0.3,
"frequency_penalty": 0.3,
"penalty": 400,
"penalty_decay": 0.99654026
},
"state": "00000000-0000-0000-0000-000000000000"
}
Reference API Return Result
{
"object": "text_completion",
"model": "assets/models\\RWKV-x060-World-3B-v2.1-20240417-ctx4096.st",
"choices": [
{
"text": " Paris, France",
"index": 0,
"finish_reason": "stop"
}
],
"usage": {
"prompt": 11,
"completion": 4,
"total": 15,
"duration": {
"secs": 0,
"nanos": 260801800
}
}
}
Explanation of the Return Result:
object: Type of the returned object, fixed as "text_completion"model: Path of the currently used modelchoices: Array of generated results, containing the following fields:text: Generated text contentindex: Index number of the resultfinish_reason: Reason for the stop of generation
usage: Usage statistics information, containing the following fields:prompt: Number of tokens in the input promptcompletion: Number of tokens in the generated contenttotal: Total number of tokensduration: Generation time consumption, including seconds and nanoseconds
api/oai/chooses
API Function: The API has "input" and "choices" parameters. That is, given the input and options, the model ranks the options according to perplexity to select the most appropriate answer.
api/oai/chooses and api/oai/v1/chooses are the same API.
API Address: (post) http://localhost:65530/api/oai/chooses
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| input | Required | Array<String> | Array of input texts provided to the model |
| choices | Required | Array<String> | Array of options for the model to choose from |
| state | Optional | string | Specify the UUID of the RWKV state file to use |
Reference API Request Body
{
"choices": [
" Paris",
" Seattle",
" San Francisco",
" Shanghai"
],
"input": [
"The Eiffel Tower is located in the city of"
],
"state": "00000000-0000-0000-0000-000000000000"
}
Reference API Return Result
{
"object": "list",
"model": "assets/models\\RWKV-x060-World-3B-v2.1-20240417-ctx4096.st",
"data": [
{
"object": "choice",
"index": 0,
"rank": 0,
"choice": " Paris",
"perplexity": 0.031040953
},
{
"object": "choice",
"index": 2,
"rank": 1,
"choice": " San Francisco",
"perplexity": 6.299065
},
{
"object": "choice",
"index": 3,
"rank": 2,
"choice": " Shanghai",
"perplexity": 12.735298
},
{
"object": "choice",
"index": 1,
"rank": 3,
"choice": " Seattle",
"perplexity": 14.686427
}
]
}
Explanation of the Return Result:
object: Type of the returned object, fixed as "list"model: Path of the currently used modeldata: Array of selection results, containing the following fields:object: Type of the option, fixed as "choice"index: Index of the option in the original choices arrayrank: Rank of the option after sorting (0 is the best choice)choice: Content of the optionperplexity: Perplexity score. The lower the score, the more suitable the option is
api/oai/embeddings
API Function: api/oai/embeddings and api/oai/v1/embeddings are the same API. They use the currently loaded RWKV model to generate embedding vectors for the given text, and the number of model layers for generating the embedding vectors can be specified.
API Address: (post) http://localhost:65530/api/oai/embeddings
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| input | Yes | ( null | string | array<string> ) | Text for the embedding model |
| layer | Yes | integer | Specify the number of layers for generating the embedding vectors |
| state | Yes | string | Specify the path of the RWKV state file to use |
Reference API Request Body
{
"input": "rwkv",
"layer": 0,
"state": "00000000-0000-0000-0000-000000000000"
}
Reference API Return Result
{
"object": "list",
"model": "assets/models\\RWKV-x060-World-1B6-v2.1-20240328-ctx4096.st",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": "embedding": [0.37109375, -0.015655518, -0.01977539, /* ... */]
}
],
"usage": {
"prompt": 2,
"completion": 1,
"total": 3,
"duration": {
"secs": 0,
"nanos": 2200
}
}
}
Explanation of the Return Result:
object: Type of the returned object, fixed as "list"model: Path of the currently used modeldata: Array of embedding vector results, containing the following fields:object: Type of the embedding object, fixed as "embedding"index: Index number of the resultembedding: Generated array of embedding vectors, containing multiple floating-point numbersusage: Usage statistics information, containing the following fields:prompt: Number of tokens in the input promptcompletion: Number of tokens in the generated contenttotal: Total number of tokensduration: Generation time consumption, including seconds and nanoseconds
api/oai/embeds
API Function: api/oai/embeds and api/oai/v1/embeds are the same API, which uses a third-party model to generate embedding vectors for the given text.
Warning
This API calls a third-party embedding model to generate embedding vectors. Before using the API, you need to open the \assets\configs\Config.toml configuration file and uncomment the last five lines of configuration code at the bottom:
[embed]
endpoint = "https://hf-mirror.com"
home = "assets/models/hf"
lib = "assets/ort/onnxruntime.dll"
name = { MultilingualE5Small = {} }
Save the configuration file and restart Ai00, and the third-party model will be automatically downloaded. The download process in the terminal is shown in the figure:

After the model is downloaded, you can use this API.
API Address: (post) http://localhost:65530/api/oai/embeds
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| input | Required | string | The text for which embedding vectors need to be generated |
| max_tokens | Optional | integer | The maximum number of tokens for text chunking, ranging from 1 to 510, with a default value of 510 |
| prefix | Optional | string | The prefix for each text chunk, with a default value of "query:" |
Reference API Request Body
{
"input": "rwkv",
"max_tokens": 510,
"prefix": "query:"
}
Reference API Return Result
{
"object": "embeds",
"model": "intfloat/multilingual-e5-small",
"data": [
{
"object": "embed",
"index": 0,
"chunks": [
{
"chunk": "The first text chunk",
"embed": [
[0.37109375, -0.015655518, -0.01977539, /* ... */]
]
},
{
"chunk": "The second text chunk",
"embed": [
[0.20153809, 0.15637207, 0.24768066, /* ... */]
]
}
]
}
]
}
Explanation of the Return Result:
object: Type of the returned object, fixed as "embeds"model: The currently used embedding modeldata: Array of embedding vector results, containing the following fields:object: Type of the embedding object, fixed as "embed"index: Index number of the resultchunks: Array of embedding vector chunks, containing the following fields:chunk: Content of the text chunkembed: Generated array of embedding vectors, containing multiple floating-point numbers
api/oai/models
API Function: api/oai/models and api/oai/v1/models are the same API, which is used to obtain information about the currently loaded model.
API Address: (get) http://localhost:65530/api/oai/models
Reference API Return Result
{
"data": [
{
"object": "models",
"id": "RWKV-x060-World-1B6-v2.1-20240328-ctx4096"
}
]
}
Explanation of the Return Result:
data: Array of model results, containing the following fields:object: Type of the model object, fixed as "models"id: The id name of the model
admin/models/load
API Function: This API is used to reload the model, LoRA, initial state, and other runtime environments.
API Address: (post) http://localhost:65530/admin/models/load
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| adapter | Optional | string | Specify the used GPU and driver backend. You can use the API api/adapters to view it. The default is "Auto" |
| bnf | Optional | object | BNF option configuration, used to configure BNF parsing related parameters. The default is empty |
| embed_device | Optional | string | Place the Embed matrix of the model on the GPU or CPU. The default is "CPU" |
| lora | Optional | array | Whether to load the LoRA file. Fill in the path of the LoRA file, the alpha value and other attributes. The default is empty |
| max_batch | Optional | integer | The maximum batch cached on the GPU, with a default value of 8 |
| model_path | Required | string | The path of the model file |
| precision | Optional | string | The precision of the intermediate tensor, with a default value of "Fp16" |
| quant_type | Optional | string | Quantization type ("Int8" or "NF4"). Int8 has better performance than NF4 but requires more VRAM |
| quant | Optional | integer | The number of quantized layers. Increasing it will improve efficiency, but it may reduce precision and deteriorate the model's performance. The default value is 0 |
| state | Optional | array | List of state files. Each element contains the path attribute. The default is empty |
| token_chunk_size | Optional | integer | The maximum number of tokens processed in parallel at one time, with a default value of 128 |
| tokenizer_path | Required | string | Specify the path of the used RWKV tokenizer |
Reference API Request Body
{
"model_path": "RWKV-x060-ChnNovel-3B-20240807-ctx4096.st",
"adapter": {
"Manual": 0
},
"quant_type": "NF4",
"quant": 31,
"token_chunk_size": 128,
"max_batch": 16,
"tokenizer_path": "assets/tokenizer/rwkv_vocab_v20230424.json",
"embed_device": "Cpu",
"precision": "Fp16",
"lora": [
{
"alpha": 192,
"path": "test-x606-3B.lora"
}
],
"state": [
{
"path": "rwkv-x060-chn_single_round_qa-3B-20240516-ctx2048.state"
}
]
}
Explanation of the Return Result:
- This API has no direct return value.
- A response status code of 200 indicates that the request was successful.
- If the loading fails, the corresponding error status code and error message will be returned.
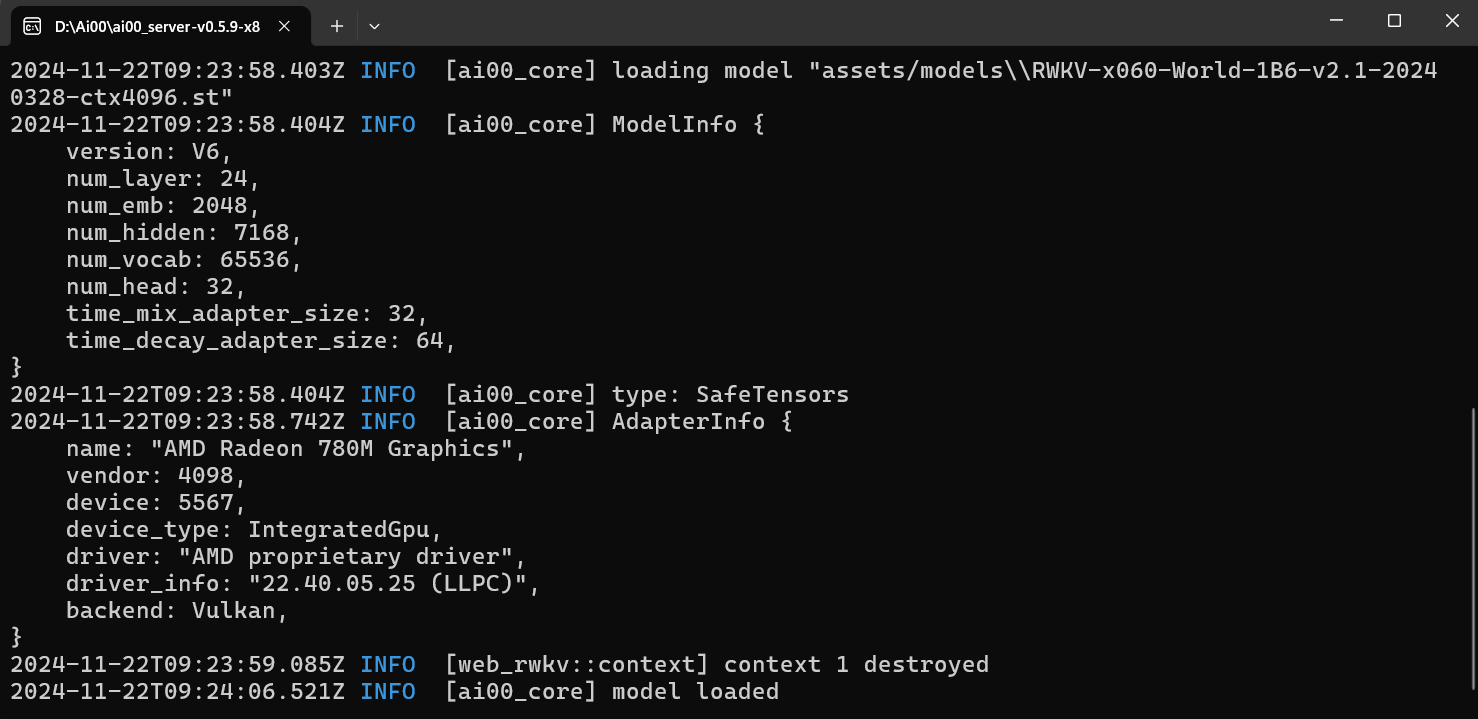
- The loading status and progress can be viewed in the terminal where the Ai00 service is deployed.
admin/models/save
API Function: This API can export the RWKV model with two configurations of quantization method and number of quantization layers in the .prefab format.
Tips
The .prefab prefab usually refers to a resource format used in game development, allowing developers to create, save, and reuse game objects (GameObjects) and the configurations of their components.
Ai00 supports importing and exporting RWKV models in the .prefab format, saving loading time by pre-quantizing the RWKV model.
API Address: (post) http://localhost:65530/admin/models/save
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| path | Required | string | The path to export the .prefab RWKV model |
Reference API Request Body
{
"path": "/assets/models/temp.st"
}
Explanation of the Return Result:
- This API has no direct return value.
- A response status code of 200 indicates that the request was successful.
- The export progress and result can be viewed in the terminal where the service is deployed.
- After a successful export, a model file in the
.prefabformat will be generated at the specified path.

admin/models/state/load
API Function: Mount the state file at the specified path.
Tips
As an RNN model, the RWKV model has a hidden state (State) of a fixed size. By loading the State file, the hidden state of the RWKV model can be initialized to enhance the performance of the RWKV model in specific tasks (similar to a model enhancement plugin).
API Address: (post) http://localhost:65530/admin/models/state/load
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| default | Optional | boolean | Whether to mount this state immediately |
| id | Optional | string | The UUID of the state file. If not specified, it will be randomly assigned |
| name | Optional | string | null | Name the state file |
| path | Required | string | The name of a certain state file in the assets\models directory |
Reference API Request Body
{
"default": false,
"id": "00000000-0000-0000-0000-000000000000",
"name": "Single-round Chinese Conversation",
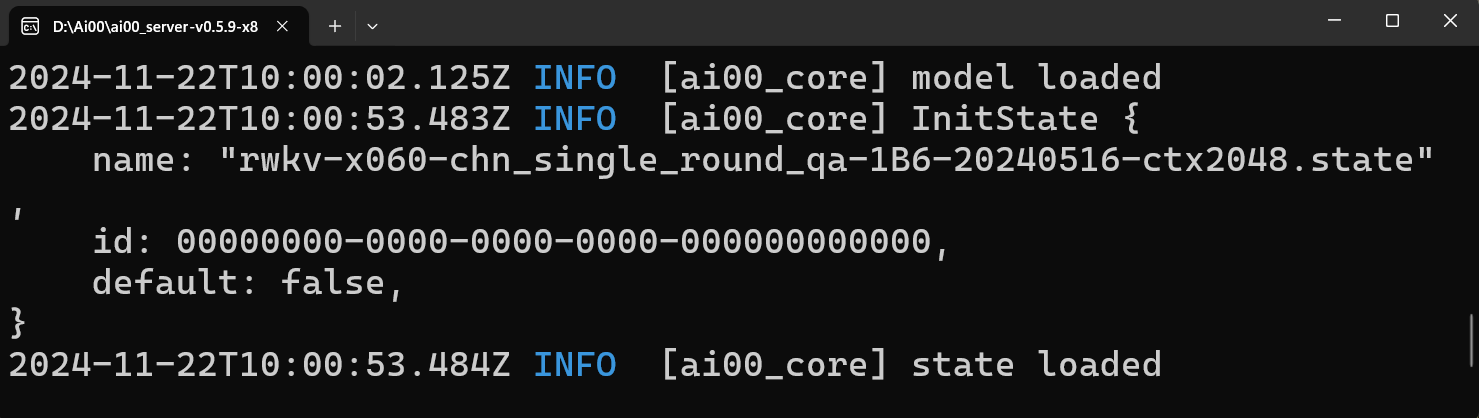
"path": "rwkv-x060-chn_single_round_qa-1B6-20240516-ctx2048.state"
}
Explanation of the Return Result:
- This API has no direct return value.
- A response status code of 200 indicates that the request was successful.
- If
defaultis specified astrue, this state will take effect immediately. - The loading status of the state file can be viewed in the terminal where the Ai00 service is deployed.
admin/models/unload
API Function: Close the currently loaded model and the Ai00 service.
API Address: (get) http://localhost:65530/admin/models/unload
Explanation of the Return Result:
- This API has no direct return value.
- A response status code of 200 indicates that the request was successful.
- After a successful unloading, the model needs to be reloaded to continue using the service.
- The unloading status can be viewed in the terminal where the Ai00 service is deployed.

api/adapters
API Function: Return all the GPUs and drivers of the current device, which are used to specify the GPU when loading the model.
API Address: (get) http://localhost:65530/api/adapters
Reference API Return Result
[
"AMD Radeon 780M Graphics (Vulkan)",
"AMD Radeon 780M Graphics (Vulkan)",
"AMD Radeon 780M Graphics (Dx12)",
"AMD Radeon 780M Graphics (Dx12)",
"AMD Radeon 780M Graphics (Gl)"
]
Explanation of the Return Result:
- Return an array of strings, where each element represents an available GPU device and its driver type.
- The format of each element in the array is:
"GPU Name (Driver Type)", such as"AMD Radeon 780M Graphics (Vulkan)". - The index of the array (starting from 0) can be used as the
adapterparameter in theadmin/models/loadAPI. For example,"adapter": {"Manual": 0}specifies to use the first GPU.
Warning
As of version 0.5.9, Ai00 only supports Vulkan drivers and no longer supports OpenGL and DirectX drivers.
api/auth/exchange
API Function: Switch the account with administrator privileges. The app_id and app_secret need to be configured in config.toml in advance.
API Address: (post) http://localhost:65530/api/auth/exchange
Parameter List:
| Parameter Name | Optional | Type | Parameter Explanation |
|---|---|---|---|
| app_id | Required | string | The app_id configured in config.toml |
| app_secret | Required | string | The app_secret configured in config.toml |
Reference API Request Body
{
"app_id": "admin",
"app_secret": "ai00_is_good"
}
Reference API Return Result
{
"token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzaWQiOiJhZG1pbiIsImV4cCI6MTczMjM1MjMwMH0.06fDScO-9GxF6rlq1v7MaC608uKg8qNN-TWZ8HvyZDk",
"code": 200,
"message": "SUCCESS"
}
Explanation of the Return Result:
token: The generated JWT authentication token, which is used for identity authentication in subsequent API requests.code: The status code, where 200 indicates success.message: The status information, where "SUCCESS" indicates success.
Sampling Methods of Ai00
Ai00 uses the Nucleus (also known as top_k) sampling method by default, which is also the default decoding method of the RWKV model. However, in addition to Nucleus, Ai00 also supports two other sampling methods, Mirostat and Typical.
Different sampling methods have different decoding parameters. Adjusting various decoding parameters of the model will affect indicators such as the content style and quality of the model's generated output.
The following is a brief description of the three sampling methods of Ai00 and the corresponding model decoding parameters:
Nucleus Sampling
The Nucleus (also known as top_k) sampling method selects the words generated by the model through cumulative probability (top_p), ensuring that the text is diverse and does not deviate from the topic.
The Nucleus sampling method supports the following decoding parameters:
| Parameter Name | Type | Parameter Explanation |
|---|---|---|
| frequency_penalty | number | Presence penalty, penalizes words that have already appeared to reduce the chance of their reappearance. |
| penalty | integer | Penalty half-life. The model adjusts the penalty_decay after outputting enough words. It is not recommended to modify this parameter. |
| penalty_decay | number | Decay parameter for frequency, gradually reducing the penalty value in each generation step, ranging from [0.99, 0.999]. It is not recommended to modify this parameter. |
| presence_penalty | number | Frequency penalty, penalizes words that appear more frequently to reduce the chance of their frequent reappearance. |
| temperature | number | Sampling temperature (which can be understood as randomness). The larger the value, the stronger the randomness and creativity, but it may also lead to incoherence in the context. |
| top_k | integer | The number of candidate words when the model generates content (similar to the number of candidate words in an input method). |
| top_p | number | The cumulative probability of the model's generation. The larger this value, the more diverse the generated content, but it is also more likely to deviate from the conversation topic or even produce nonsensical output. |
In an API request of Ai00, the standard Nucleus sampling format is as follows:
{
"sampler_override": {
"frequency_penalty": 0.3,
"penalty": 400,
"penalty_decay": 0.99654026,
"presence_penalty": 0.3,
"temperature": 1,
"top_k": 128,
"top_p": 0.5,
"type": "Nucleus"
}
}
Mirostat Sampling
Mirostat sampling balances creativity and coherence by dynamically adjusting the entropy (randomness).
| Parameter Name | Type | Parameter Explanation |
|---|---|---|
| Rate | number | The speed at which the model adjusts the randomness. A higher Rate value will make the model adapt to the new context faster, but it may lead to incoherence in the topic of the answer. |
| tau | number | The target randomness when the model generates text. A higher tau value will result in more creative and diverse text generated by the model, but it may lead to less coherent content. |
In an API request of Ai00, the standard Mirostat sampling format is as follows:
{
"sampler_override": {
"Rate": 0.09,
"tau": 0.5,
"type": "Mirostat"
}
}
Typical Sampling
Typical sampling selects the most representative words in the context to avoid the derailment of content caused by extreme probabilities.
| Parameter Name | Type | Parameter Explanation |
|---|---|---|
| frequency_penalty | number | Presence penalty, penalizes words that have already appeared to reduce the chance of their reappearance. |
| penalty | integer | Penalty half-life. The model adjusts the penalty_decay after outputting enough words. It is not recommended to modify this parameter. |
| penalty_decay | number | Decay parameter for frequency, gradually reducing the penalty value in each generation step, ranging from [0.99, 0.999]. It is not recommended to modify this parameter. |
| presence_penalty | number | Frequency penalty, penalizes words that appear more frequently to reduce the chance of their frequent reappearance. |
| temperature | number | Sampling temperature (which can be understood as randomness). The larger the value, the stronger the randomness and creativity, but it may also lead to incoherence in the context. |
| top_k | integer | The number of candidate words when the model generates content (similar to the number of candidate words in an input method). |
| tau | number | The target randomness when the model generates text. A higher tau value will result in more creative and diverse text generated by the model, but it may lead to less coherent content. |
In an API request of Ai00, the standard Typical sampling format is as follows:
{
"sampler_override": {
"frequency_penalty": 0.3,
"penalty": 400,
"penalty_decay": 0.99654026,
"presence_penalty": 0.3,
"temperature": 1,
"top_k": 128,
"tau": 5,
"type": "Typical"
}
}
Frequently Asked Questions
Failed to Load When Accessing https://localhost:65530
A: If you have set tls = false in Config.toml, you need to change https to http, that is, access http://localhost:65530.
Why is TLS still enabled when I change tls=true to tls=false in the config during startup?
A: If ACME is set, TLS will be enabled regardless.
It runs successfully on my own computer but reports an error on some cloud platforms.
A: The cloud platform may not support Vulkan, and you need to check if Vulkan is available.
Why does it feel like only one graphics card is working when running AI00 while my computer has multiple graphics cards?
A: AI00 does not support multi-graphics card inference for now.
Error: ERROR [ai00 server::middleware] reload model failed: failed to request adaptor
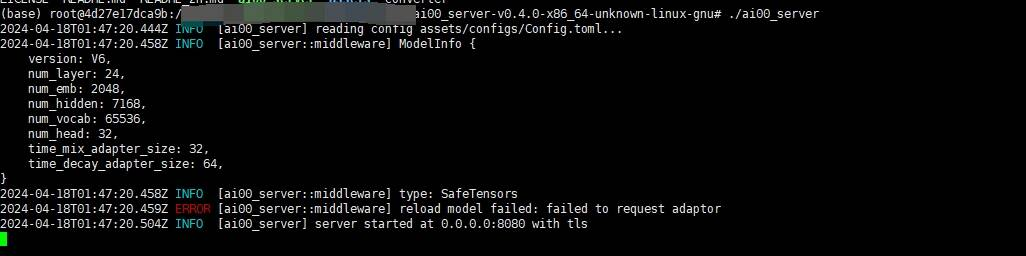
A: This is because the device lacks the Vulkan driver. Please install the latest version of the driver.
Does AI00 support CUDA drivers?
A: No, it doesn't. AI00 supports Vulkan as the inference backend. It once supported Dx12/openGL, but it does not support CUDA drivers.
Why does it seem that the speed becomes slower after I use shared VRAM?
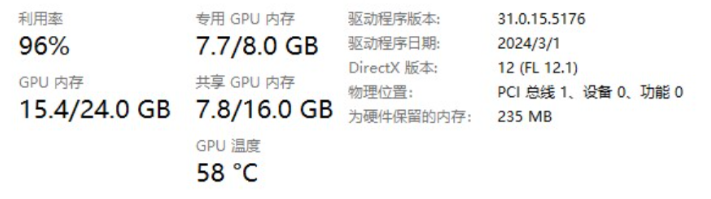
A: Once shared VRAM is used, the running speed will be 20 times slower. This is due to the working principle of computer hardware and is not a bug.