
Preparing The Training Datasets
Follow the steps below to organize your training dataset of RWKV model.
Organizing jsonl Data
First, confirm what knowledge you want the RWKV model to learn. This knowledge can be materials from a certain field, such as legal Q&A, financial knowledge, etc.; or it can be texts for a certain type of task, such as material summarization, role-playing, etc.
In short, you need to collect the corresponding data according to the specific task requirements and organize it into a file in the jsonl format.
The following is a reference for the jsonl format for different content types/task types:
Single-round Question and Answer
Single-round question and answer is usually used to train downstream tasks such as chatbots. The data format is:
{"text": "User: Question\n\nAssistant: Answer"}
An example of a single-round question and answer:
{"text": "User: What is water?\n\nAssistant: Water is a colorless, odorless, and tasteless liquid, and it is one of the most common substances on Earth."}
In this example, the content after User: is usually the input given to the model by humans, and the content after Assistant: is the answer given by the model.
Tips
In addition to User and Assistant, you can also add the System role to provide background settings or strengthen the model's recognition of the Assistant: role.
{"text": "System: You are an excellent tour guide proficient in the history and geography of Guangdong.\n\nUser: Tour guide, what is the capital city of Guangdong?\n\nAssistant: The capital city of Guangdong is Guangzhou, which has a very long history."}
{"text": "System: It is the period of the Three Kingdoms, and the world is in chaos with many warlords vying for power. You are a soldier fighting against Zhang Fei.\n\nUser: Boy, take this sword from Zhang Fei!\n\nAssistant: Please spare my life, Brother Zhang Fei!"}
The System role is also applicable to the multi-round conversation data below.
Multi-round Conversation
Multi-round conversation data is suitable for task scenarios of continuous conversation and context understanding, such as customer service robots and role-playing.
The format of multi-round conversation data is:
{"text": "User: Question 1\n\nAssistant: Answer 1\n\nUser: Question 2\n\nAssistant: Answer 2"}
An example of a multi-round conversation:
{"text": "User: Good evening!\nNice to meet you!\n\nAssistant: Good evening!\nNice to meet you too!\n\nUser: I'm ten years old this year.\nHow old are you?\n\nAssistant: I'm five years old this year."}
Warning
Note that User: and Assistant: need to be separated by \n\n. But line breaks within the conversation content can only be represented by \n.
Instruction Question and Answer
Instruction-based question and answer data is suitable for summarization tasks such as information extraction, material summarization, and meeting minutes, and it is also the recommended format for instruction tuning.
{"text": "Instruction: Instruction\n\nInput: Content\n\nResponse: Answer"}
Among them, Instruction is the instruction given to the model, Input is the content input given to the model, and Response is the answer given by the model.
Tips
An English space should be inserted between Instruction:, Input:, Response: and the text content.
In addition, Instruction:, Input:, and Response: need to be separated by \n\n. But line breaks within the conversation content can only be represented by \n.
An example of an instruction-based question and answer:
{ "text": "Instruction: Please determine which category the following sentence belongs to. The categories include culture, entertainment, sports, finance, real estate, automobiles, education, technology, military, tourism, international affairs, securities, agriculture, e-sports, and people's livelihood. Please directly output the category without any additional content.\n\nInput: The RWKV large model officially launched the seventh-generation architecture RWKV-7.\n\nResponse: Technology"}
The content of Instruction: and Input: will be concatenated and used as the input to the model, and the content of Response: is the answer given by the model.
In this example, the model will receive the following input:
Please determine which category the following sentence belongs to. The categories include culture, entertainment, sports, finance, real estate, automobiles, education, technology, military, tourism, international affairs, securities, agriculture, e-sports, and people's livelihood. Please directly output the category without any additional content.
The RWKV large model officially launched the seventh-generation architecture RWKV-7.
The model will give the following output:
Technology
Long Text Data(Articles/Novels)
Long text data such as articles and novels is usually used to train continuous long text generation tasks such as text continuation and text expansion.
For long text content such as whole novels and extremely long articles, the data format is:
{"text": "Turn the content of each article into one line of JSONL, even if it is a novel with one million words."}
For short content with titles such as news and announcements, the data format is:
{"text": "《Title》\nBody content"}
For the task of continuing a single paragraph of a novel or article, the data format is:
{"text": "User: The beginning of a paragraph of about 100 words\n\nAssistant: The subsequent text of the paragraph"}
For the task of expanding a novel paragraph from a novel outline, the data format is:
{"text": "User: The outline of the chapter\n\nAssistant: The complete content of the chapter"}
More Details of the Training Data
How Much Data is Needed
There is no strict specification for the quantity of fine-tuning training data. It can be several hundred pieces, several thousand pieces, or even more.
Generally, the more data there is, the better the effect of fine-tuning training will be. But high-quality data requires a large amount of time and human resources. Therefore, it needs to be adjusted according to the actual situation:
- Adjust according to the complexity of the fine-tuning task: For simple classification or summarization tasks, maybe only a few hundred pieces of data are needed. For complex role-playing or text generation tasks, several thousand pieces or more of data are required.
- Quality is more important than quantity: High-quality data should accurately reflect the characteristics of the target task and cover diverse scenarios and expressions.
The adjustment of training data is a step-by-step iterative process, which usually needs to go through the following steps:
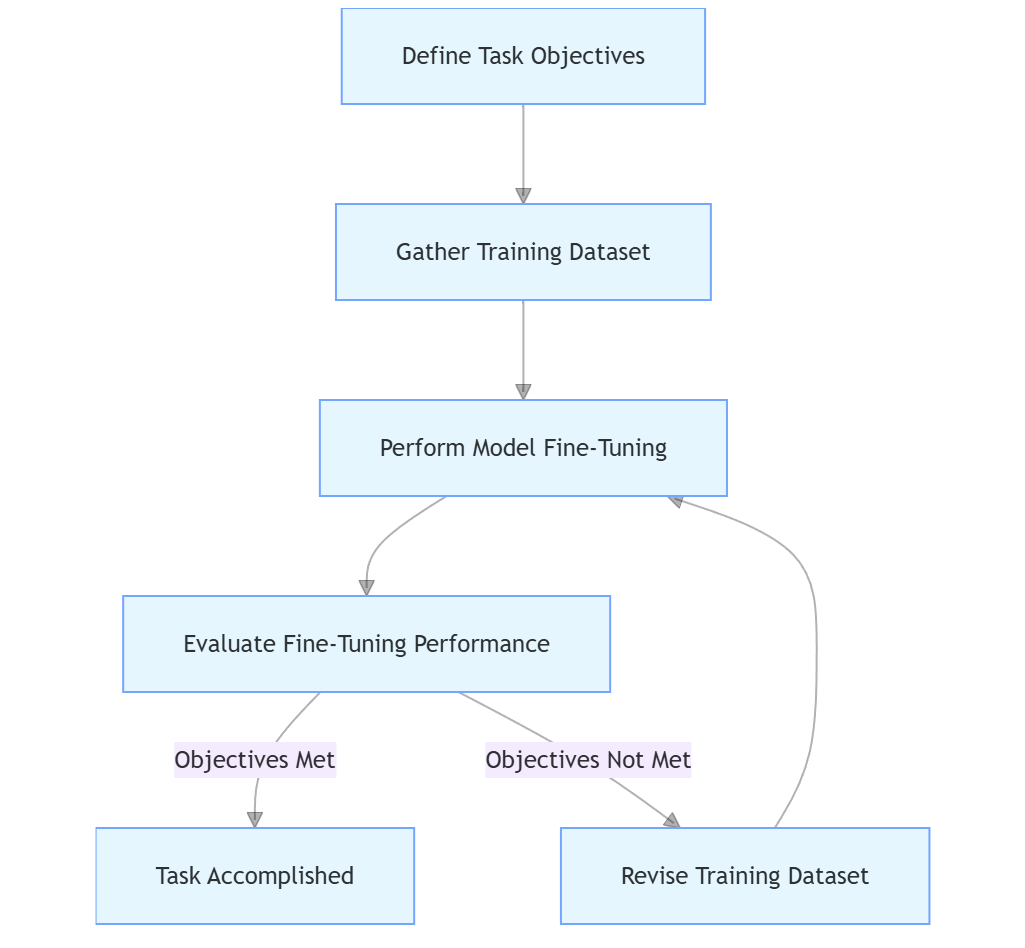
Until a satisfactory fine-tuning effect is obtained.
Duplicating and Shuffle the Data
When the training data is insufficient, duplicating the training data helps to enhance the model's understanding and memory of specific knowledge, and shuffling the data order is to reduce the risk of overfitting.
On Linux or Mac systems, use the following commands to repeat and shuffle the data file:
# Repeat the data.jsonl file three times and output all lines to the repeated-data.jsonl file
# This command can also be used to merge multiple jsonl data files
awk 'NR > 1 && NF == 0 {next} {print}' data.jsonl data.jsonl data.jsonl > repeated-data.jsonl
# Shuffle the lines of the repeated-data.jsonl file and output the shuffled result to the shuffled-data.jsonl file
shuf repeated-data.jsonl > shuffled-data.jsonl
Tips
data.jsonl needs to be replaced with the name of the jsonl data file you have prepared.
Tips
On Windows systems, you can use WSL (Windows Subsystem for Linux) or install the Cygwin tool to use the awk and shuf commands.
Adding Conventional Data
It is recommended to add some conventional data to the fine-tuning dataset. Adding conventional data helps to enhance the model's generalization ability and reduce the risk of overfitting at the same time.
Suppose we are fine-tuning a model for answering elementary math problems, and the data samples are similar to this:
{"text": "User: 1 + 1 = ?\n\nAssistant: 2"}
{"text": "User: 1 + 2 = ?\n\nAssistant: 3"}
{"text": "User: 1 + 3 = ?\n\nAssistant: 4"}
At this time, we can add some other expressions of math problems and conventional conversation data in non-math fields to the dataset, such as:
{"text": "User: 1 + 1 = ?\n\nAssistant: 2"}
{"text": "User: I have 5 apples and give 2 to Xiaoming. How many are left?\n\nAssistant: 3 apples"}
{"text": "User: What is the sum of 8 and 7?\n\nAssistant: 15"}
{"text": "User: The area of a rectangle is 20 square meters and the width is 4 meters. So what is its length?\n\nAssistant: The length is 5 meters."}
{"text": "User: What's the weather like today?\n\nAssistant: It's sunny today, and it's suitable for going out and having fun."}
{"text": "User: 1 + 2 = ?\n\nAssistant: 3"}
Converting jsonl Files to binidx Files
After obtaining the training data in the jsonl format, we need to use the json2binidx tool to convert the jsonl file into a binidx file that is more suitable for RWKV training.
The following prompt means that the conversion is complete:

You should be able to find the converted bin/idx files in the data folder:

At this time, our preparatory work is over. Next, we need to select a fine-tuning method and read the corresponding documentation in the following articles.