
RWKV Architecture History
Tips
If you are not familiar with machine learning, I would highly recommend Andrej Karpathy's series on neural networks - that would help provide a good foundation on various neural network architecture concepts.
The following is knowledge related to the RWKV architecture, including the origin of the RWKV architecture name, RWKV architecture features, architecture history, and model releases for each architecture.
RWKV is a variant of RNN. Therefore, it is necessary to first introduce: What is the RNN architecture, and what is the hidden state of the RNN architecture?
RNN Architecture and Hidden State
Recurrent Neural Network (RNN) is a neural network model widely used in the field of deep learning.
During the operation of the RNN network, a hidden state (state) is maintained, which can be regarded as the "mental state" of the RNN model. When humans think, the brain retains the "key information" most relevant to the current event. As the content of thinking changes, the "key information" in our minds is constantly updated. Similarly, the RNN network continuously updates its hidden state through specific functions.
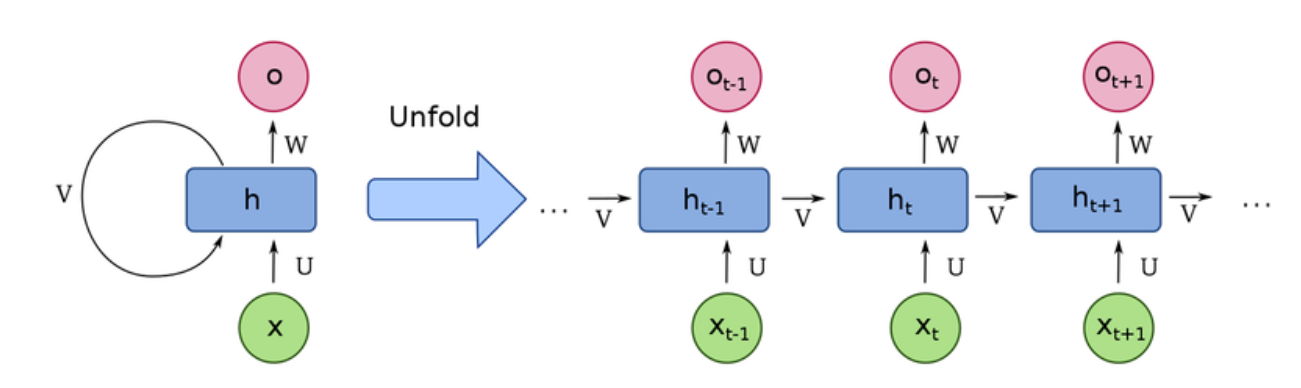
As shown in the figure, the RNN network processes each input token in sequence and predicts the next possible token (if needed) based on the "current hidden state". After processing a token, the RNN feeds the result back to the neural network, thereby "updating its hidden state"; then, RNN uses the "updated state" to predict the next token. This cycle continues until the "task completion" state is reached.
Info
As a variant of RNN, RWKV supports fine-tuning of the hidden state (state tuning). After tuned with specific "mental state", RWKV performs better on various downstream tasks.
What does RWKV stands for
The name of the RWKV architecture comes from the four main parameters used in the time-mixing and channel-mixing blocks:
Development History of the RWKV Architecture
In 2020, BlinkDL began researching Transformers and immediately discovered two obvious improvement directions: introducing explicit decay and Token-shift (or short convolution). After testing on https://github.com/BlinkDL/minGPT-tuned, he found that these techniques significantly improved the performance of Transformers.
Later, he noticed Apple's Attention Free Transformer (AFT) paper and tested it, finding that these two techniques also brought significant performance improvements to AFT.
RWKV-V1
In August 2021, the first version of the RWKV architecture: RWKV-V1 released on RWKV-LM repository. The first commit of RWKV-V1 was on August 9, 2021.
RWKV-V1 uses long convolution instead of the Attention mechanism while its architecture consists of alternating Time-mix and Channel-mix. Channel-mix is a variant of the Transformer's GeGLU layer. Time-mix is a significant improvement over AFT:
where
Tips
The structure design of Time-mix and Channel-mix is based on the four main parameters
Warning
RWKV-V1 is closer to Linear Transformer rather than RNN, as each time step depends on all previous inputs.
RWKV-V2-RNN
The RWKV-V2 version was the first RNN model of RWKV, with the pseudo-code diagram as follows:

Supplementary explanation of the code diagram:
- a and b are the EMA (exponential moving average) of kv and k
- c and d are a and b plus the pure self-attention effect (self-attention at the same position)
- c / d is the memory mechanism: if a character has a strong k in a certain channel and W is close to 1, the character will be remembered by the subsequent text
- Invented a headQK mechanism, allowing the model to directly copy or avoid generating certain characters from previous text. This mechanism is important for ICL (in-context learning) and was found by other researchers years later. However, to push the limits of pure RNN model, the main RWKV model never equipped this feature.
q = self.head_q(x)[:,:T,:]
k = self.head_k(x)[:,:T,:]
c = (q @ k.transpose(-2, -1)) * (1.0 / 256)
c = c.masked_fill(self.copy_mask[:T,:T] == 0, 0)
c = c @ F.one_hot(idx, num_classes = self.config.vocab_size).float()
x = self.head(x) + c
Tips
Through exponential decay, RWKV-V2 achieved RNN-style inference: the model's current generation depends on the last output and current input, while having a fixed-size hidden state (a and b in RWKV-V2).
RWKV-V2's self-attention layer simplified expression:
RWKV-V3
RWKV-V3 is a short-term transitional version, which uses more comprehensive token-shift compared to that of RWKV-V2 (using different trainable TimeMix factors for R / K / V in SA and FF layers respectively):
xx = self.time_shift(x)
xk = x * self.time_mix_k + xx * (1 - self.time_mix_k)
xv = x * self.time_mix_v + xx * (1 - self.time_mix_v)
xr = x * self.time_mix_r + xx * (1 - self.time_mix_r)
Diagram of RWKV-V3's token-shift improvement compared to V2:
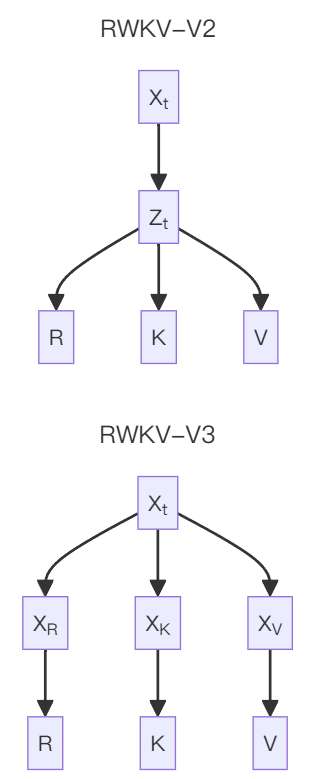
In addition, this version uses preLN instead of postLN (more stable while converges faster):
if self.layer_id == 0:
x = self.ln0(x)
x = x + self.att(self.ln1(x))
x = x + self.ffn(self.ln2(x))
RWKV-V4
RWKV-V4 is the first official version of the RWKV architecture, which is named "Dove". RWKV-V4 solved the numerical stability issues of the RWKV-V3 architecture. The first paper of the RWKV project 《RWKV: Reinventing RNNs for the Transformer Era》 is released at the same time.
The RWKV-V4 architecture paper was co-authored by RWKV author BlinkDL and the RWKV community, first published on May 22, 2023. In October of the same year, the RWKV-V4 architecture paper was accepted by EMNLP 2023.
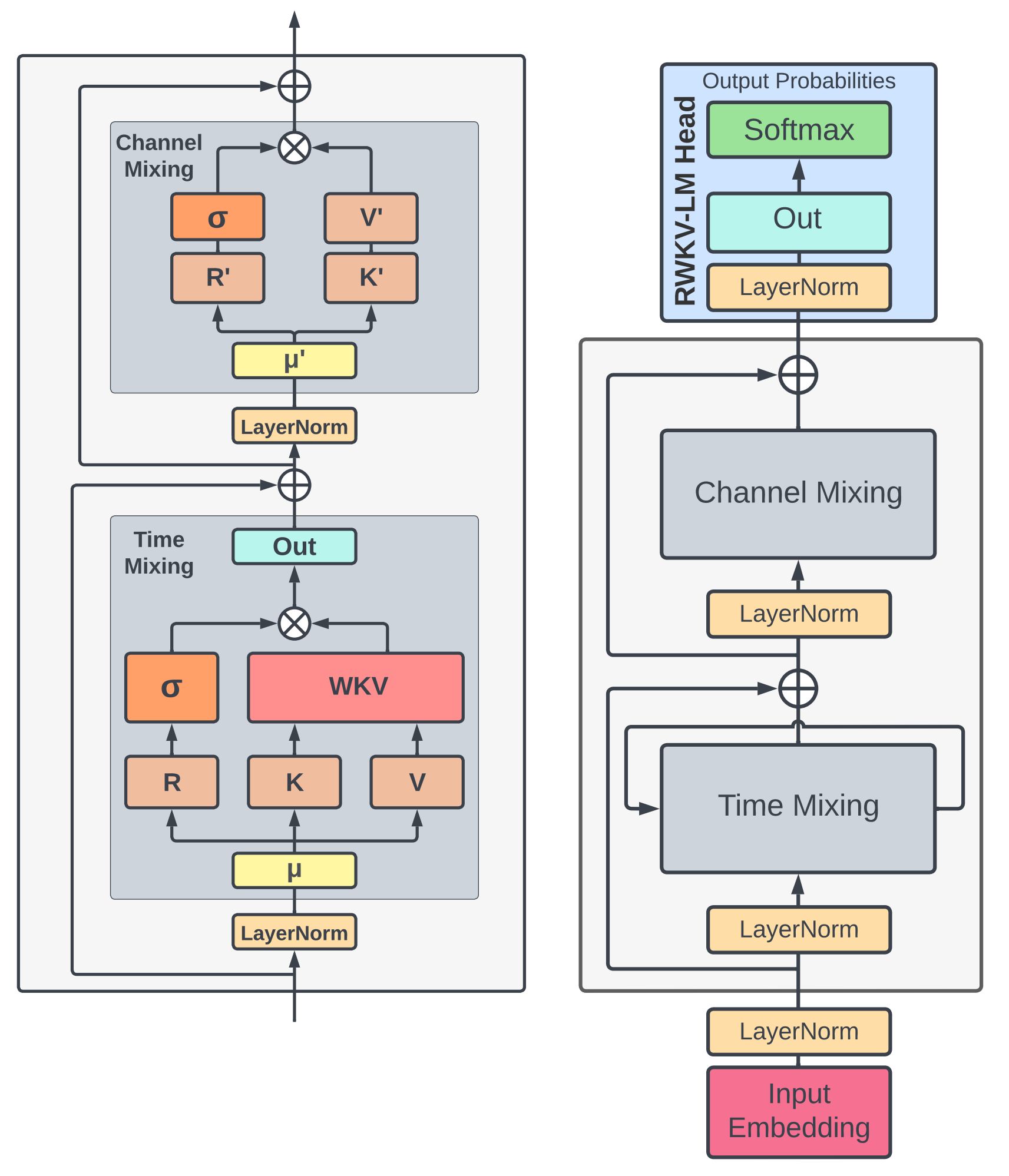
Info
The above figure is an overview of the RWKV-V4 model architecture from the paper, where:
- Left: RWKV-V4's time-mixing and channel-mixing modules
- Right: RWKV-V4's language modeling process
Token Shift Concept
The RWKV-V4 paper formally proposed the concept of "Token Shift": mixing each token with all previous token. This process is similar to a one-dimensional causal convolution with a size of 2. Token Shift allows the model to control how much new information and old information would be allocated to each head's reception, key, value, and gate vectors (i.e.,
The architecture diagram of RWKV-V4 language modeling demonstrates the Token Shift process of RWKV-V4 and the state-update process of RWKV:
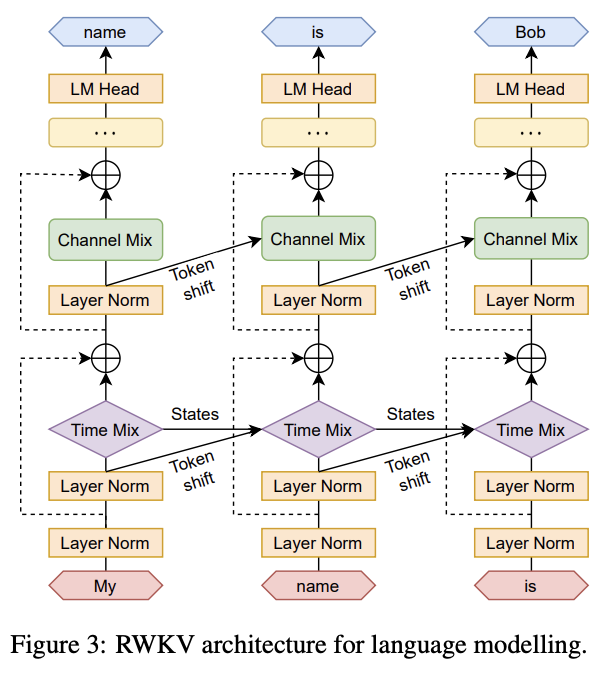
Note
A major feature of the RWKV-V4 version is that the state (RNN's hidden state) is very small, because BlinkDL focused on achieving the best performance with smallest state.
With
RWKV-V4 Model Release
The research of RWKV-V4 (architecture iteration and model training, etc.) spanned 2022 and 2023. Below are 4 types of major models released:
- RWKV-4-Pile: Pre-trained on the 331B tokens Pile dataset, including models with 169m, 430m, 1B5, 3B, 7B, and 14B parameters
- RWKV-4-Raven: Instruction fine-tuned model of RWKV-4-Pile, fine-tuned using open-source datasets such as Alpaca, CodeAlpaca, Guanaco, GPT4All, ShareGPT, including models with 1B5, 3B, 7B, and 14B parameters.
- RWKV-4-World: Multilingual model trained on the RWKV World v1 dataset (over 100 world languages, training data includes Pile), including base models with 169m, 430m, 1B5, 3B, 7B parameters, and some Chinese fine-tuned models.
- RWKV-4-Music: Music-composition models in MIDI and ABC formats, trained on bread-midi-dataset and irishman music score data. The ABC model has 82m parameters, and the MIDI models have 120m and 560m parameters.
RWKV-V4 Model Comparison Table:
| Model Name | Description | Training Data (Data Volume) | Vocabulary (Vocabulary Size) |
|---|---|---|---|
| RWKV-4-Pile | Pre-trained language model based on the Pile dataset | EleutherAI/pile (331B tokens) | 20B_tokenizer (50,277) |
| RWKV-4-Raven | Instruction fine-tuned language model of RWKV-4-Pile | Alpaca, CodeAlpaca, Guanaco, GPT4All, ShareGPT, etc. | 20B_tokenizer (50,277) |
| RWKV-4-World | Pre-trained language model based on a dataset of over 100 world languages | RWKV World v1 (590B tokens) | rwkv_vocab_v20230424 (65,536) |
| RWKV-4-Music (MIDI) | Music (composition) model trained on MIDI music score data | bread-midi-dataset | MIDI-LLM-tokenizer (20,095) |
| RWKV-4-Music (ABC) | Music (composition) model trained on ABC music score data | irishman | - |
In addition, RWKV-V4 trained a 14B parameter model for the first time. Moreover, from RWKV-V4-World, the World series dataset containing more than 100 world languages and the corresponding multilingual vocabulary rwkv_vocab_v20230424 were officially used.
Info
The World series dataset and rwkv_vocab_v20230424 vocabulary are used in subsequent RWKV architectures such as RWKV-V5 and RWKV-V6.
The World dataset will continue adding new training data:
- World v1 ≈ 0.59T tokens
- World v2 ≈ 1.1T tokens
- World v2.1 ≈ 1.42T tokens, total training data for v2.1 models ≈ 2.5T tokens
- World v3 ≈ 3T tokens, total training data for v3 models ≈ 5.5T tokens
RWKV-V5
RWKV-V5 is an improved version of the RWKV-V4 architecture, codename "Eagle".
RWKV-V5 and RWKV-V6 architectures were released in the same paper 《Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence》.
The paper was co-authored by RWKV author BlinkDL and the RWKV community, first published on April 9, 2024. In October of the same year, the RWKV 5/6 architecture paper was accepted by the international conference COLM 2024.
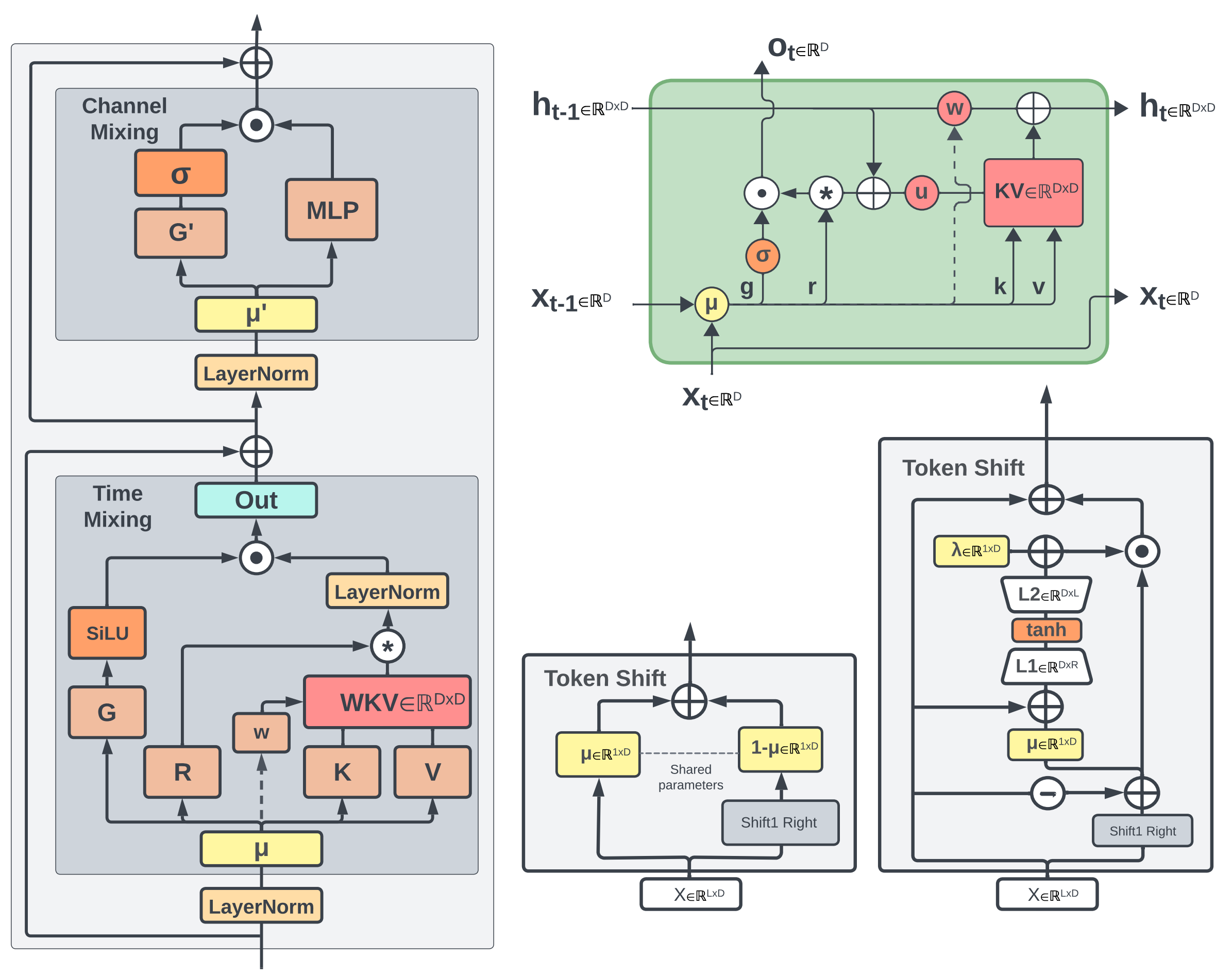
Info
The above figure is an overview of the RWKV 5/6 architecture from the paper, where:
- Left: time-mixing and channel-mixing blocks
- Top right: RWKV time-mixing block as RNN cell
- Bottom middle: token-shift module in FeedForward module and Eagle time-mixing
- Bottom right: token-shift module in Finch time-mixing
- Dashed arrows (left, top right): indicate a connection in Finch, but not in Eagle
RWKV-V5 Architecture Optimization Details
Compared to RWKV-V4, the most important change in RWKV-V5 is the introduction of multi-headed, matrix-valued states, as described in the paper.
In RWKV-V4's time mixing computation, the parameters
| State | Output | |
|---|---|---|
| 0 | ||
| 1 | ||
| 2 | ||
| 3 |
RWKV-V5 splits
The time-mixing steps for each head in RWKV-V5:
| State | Output | |
|---|---|---|
| 0 | ||
| 1 | ||
| 2 | ||
| 3 |
RWKV-V5 forward propagation (inference process) time-mixing calculation formula:
By transforming the vectors of RWKV-V4 into matrices, RWKV-V5's state calculation changes from "vector-based" to "matrix-valued states" with a dimension of 64×64, i.e., "matrix-valued states". Assuming the current RWKV model has a dimension of 512, it can be said that there are 512/64 = 8 heads (eight heads × 64 dimensions), which is the "multi-headed" concept of RWKV-V5.
Therefore, we can summarize the optimization details of RWKV-V5 as: RWKV-V5 eliminates the normalization term (the denominator in the RWKV-V4 formula) and introduces matrix-valued states instead of the previous vector-valued states.
In this way, RWKV-V5 cleverly expands the scale of the state, giving the RWKV model better memory and model capacity.
Tips
With
RWKV-V5 Iteration Process
In fact, the research of the RWKV-V5 architecture was not achieved overnight. From its proposal in July 2023 to its finalization in September 2023, the optimization process of RWKV-V5 can be divided into three sub-versions: RWKV-5.0, 5.1, and 5.2.
RWKV-5.0
RWKV-5.0 redesigned the
The RWKV-5.0 architecture only released a 0.1B model: RWKV-5-World-0.1B-v1-20230803-ctx4096, which was still trained based on the World-v1 dataset from the RWKV-V4 period.
RWKV-5.1
RWKV-5.1 introduced a Time-mixing gating mechanism on the basis of RWKV-5.0, which is an additional matrix
The RWKV-5.1 architecture only released music models: RWKV-5-ABC-82M-v1-20230901-ctx1024 and RWKV-5-MIDI-560M-v1-20230902-ctx4096.
RWKV-5.2
RWKV-5.2 introduced diagonal decay matrices on the basis of RWKV-5.1, that is, the
The RWKV-5.2 architecture released six types of models: 0.4B, 1B5, 3B, 7B, and 3B (ctx16k), which were trained based on the World-v2 dataset.
RWKV-V5 Subversion Comparison Table
| Architecture Version | Optimization Details | Released Models | Dataset |
|---|---|---|---|
| RWKV-5.0 | Redesigned the | RWKV-5-World-0.1B-v1 | World-v1 |
| RWKV-5.1 | Introduced a Time-mixing gating mechanism on the basis of RWKV-5.0, that is, an additional matrix | RWKV-5-music series, including ABC-82M and MIDI-560M | irishman, bread-midi-dataset |
| RWKV-5.2 | Introduced diagonal decay matrices on the basis of RWKV-5.1, that is, the | RWKV-5-World-V2.1 series, including 0.4B, 1B5, 3B, 7B, and 3B (ctx16k) | World-v2 |
Caution
RWKV-V5 series models are all outdated, it is recommended to use RWKV-V6 models.
RWKV-V6
The version code of RWKV-V6 is "Finch". This version was developed in October 2023 and is the currently (November 2024) stable architecture.
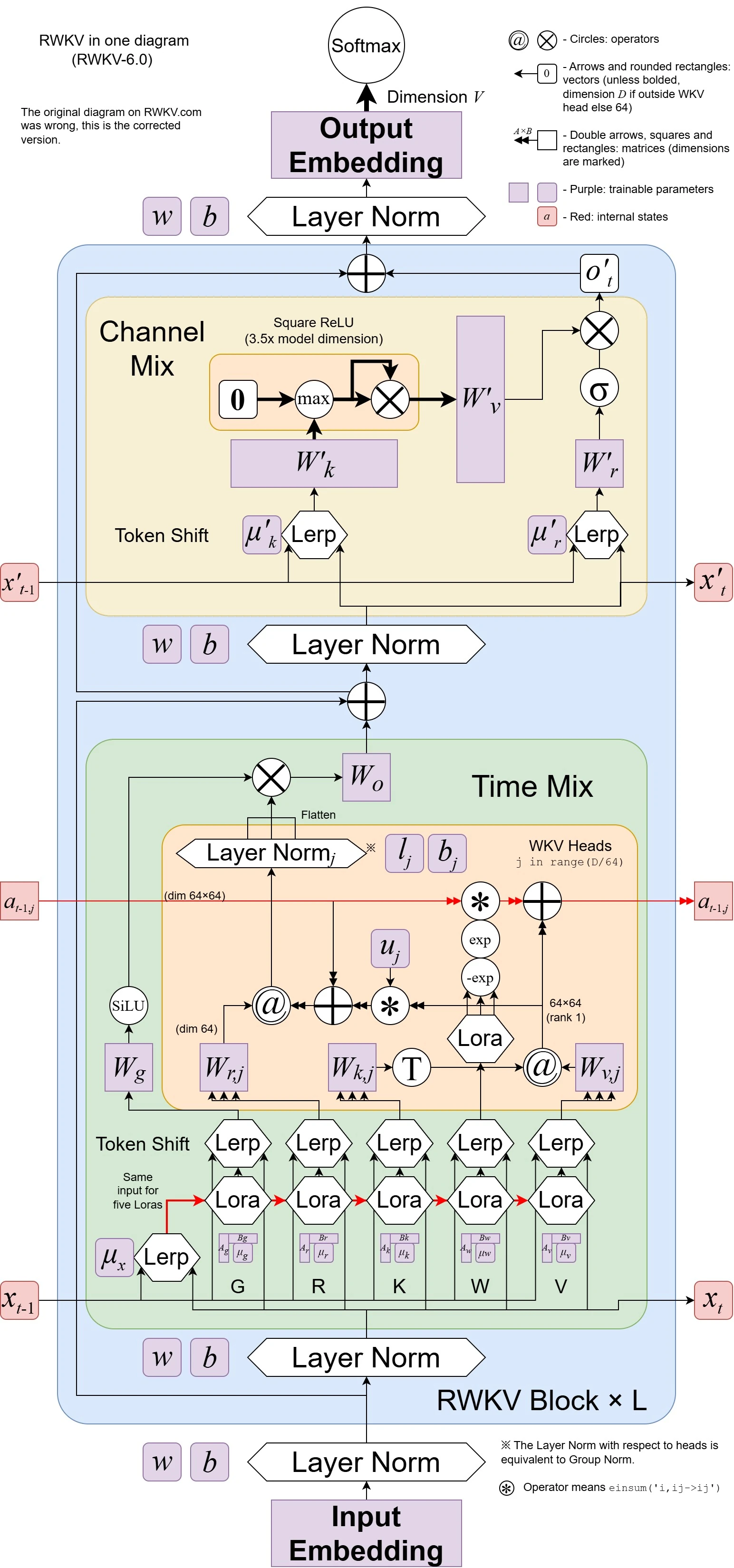
RWKV-V6 Architecture Optimization Details
RWKV-V6 introduced a dynamic recurrence mechanism based on LoRA, further optimizing the Token Shift and time-mixing processes.
RWKV-V5's Token Shift is similar to RWKV-V4, which is a very simple linear interpolation (lerp), and this linear interpolation is data-independent; parameter
In RWKV-V5's Token Shift, the linear interpolation formula between
RWKV-V6 borrowed the technology of low-rank adaptation (LoRA), replacing the static parameter
In RWKV-V6's Token Shift, the linear interpolation formula between
Compared to RWKV-V4/RWKV-V5, RWKV-V6's new Token Shift, which enhances data dependency, effectively expands the model's capabilities. The amount of new and old data allocated to each channel depends on the current input and output from last time steps.
Tips
In general, this dynamic recurrence mechanism allows "important information" to effectively mark itself for use in subsequent tasks; while "unimportant information" can also mark itself so that model can reduce the probability of or completely avoid it entering the subsequent data flow, thereby reserving space for more important existing data.
In addition, if certain information is not useful for a specific task, the dynamic recurrence mechanism filtered out this information in advance.
RWKV-V6's dynamic Time Mixing calculation formula:
The attention calculation of
Unlike RWKV-V5,
Warning
The above new LoRA mechanism is used to obtain the mixing vector. Note that the LoRA process itself uses the Token Shift value in the style of Eagle (RWKV-V5) as input (the
Intuitively, this is a second-order variant of Token Shift, allowing each channel of
RWKV-V6 Model Release
The RWKV-V6 architecture itself does not have sub-versions, but different types of models have been released, including base models pre-trained with different training sets, as well as Chinese novel and Japanese fine-tuned models. The following is an overview of models based on the RWKV-V6 architecture:
| Model Category | Model Status | Model Description | Training Data |
|---|---|---|---|
| RWKV-6-World-v2 | Outdated | Multilingual pre-trained model based on the World-v2 dataset | World-v2 |
| RWKV-6-World-v2.1 | Stable | Multilingual pre-trained model based on the World-v2.1 dataset | World-v2.1 |
| RWKV-6-World-v3 | In Training | Multilingual pre-trained model based on the World-v3 dataset | World-v3 |
| RWKV-6-ChnNovel | Stable | Chinese novel fine-tuned model, fine-tuned with Chinese novel + instruction data based on RWKV-6-World-v2.1 | World-v2.1, Chinese novel data |
| RWKV-6-Jpn | Stable | Japanese fine-tuned model, fine-tuned with Japanese + instruction data based on RWKV-6-World-v2.1 | World-v2 |
RWKV-V6 State Tuning
Tips
In addition to the complete model weights, RWKV community developed state tuning during the iteration of the RWKV-V6 architecture. This is a novel fine-tuning method that fine-tunes the initial state of RWKV, which is equivalent to the most efficient prompt tuning. This method is excellent at alignment because of its strong transferability. For detailed methods of state tuning, please refer to RWKV-PEFT - State Tuning.
The fine-tuned state file can be merged into the base model or used as an "enhancement plugin for the RWKV model": that is, initializing the model's state before loading the base RWKV model to affect the model's response style, response format, etc.
RWKV officially released different types of state files:
| State Type | State Description | Applicable RWKV Model |
|---|---|---|
| chn-single-round | Enhanced Chinese single-round dialogue, more in line with human language habits, with rich Emoji expressions | RWKV base model |
| eng-single-round | Enhanced English single-round dialogue, more in line with human language habits, with rich Emoji expressions | RWKV base model |
| chn-小说扩写-single-round | Chinese single-round dialogue, will expand the novel based on user input (it is recommended to use RWKV-V6-ChnNovel model and state as a replacement) | RWKV base model |
| chn-打油诗-single-round | Chinese single-round dialogue, will create doggerel based on user input | RWKV base model |
| chn-文言文-single-round | Chinese single-round dialogue, the response style will be biased towards classical Chinese | RWKV base model |
| chn-文言文和古典名著-single-round | Chinese single-round dialogue, the response style will be biased towards classical Chinese and classical literature | RWKV base model |
| OnlyForChnNovel_小说扩写 | Used to expand Chinese novels, suitable for RWKV-V6-ChnNovel models of the same size | RWKV-V6-ChnNovel |
RWKV-V7
The architecture code of RWKV-7 is "Goose". RWKV-7 surpasses the attention/linear attention paradigm, its "state evolution" is very flexible, which can solve problems that attention cannot solve with the same computational cost. At the same time, RWKV-7 surpasses the TC0 constraint.
The research of RWKV-7 began in September 2024, and its preview version RWKV-7 "Goose" x070.rc2-2409-2r7a-b0b4a's training code was first released at the commit of the RWKV-LM repository.
Tips
The paper on the RWKV-V7 architecture, "RWKV-7 "Goose" with Expressive Dynamic State Evolution", was officially released on March 18, 2025.
Paper link: https://arxiv.org/abs/2503.14456
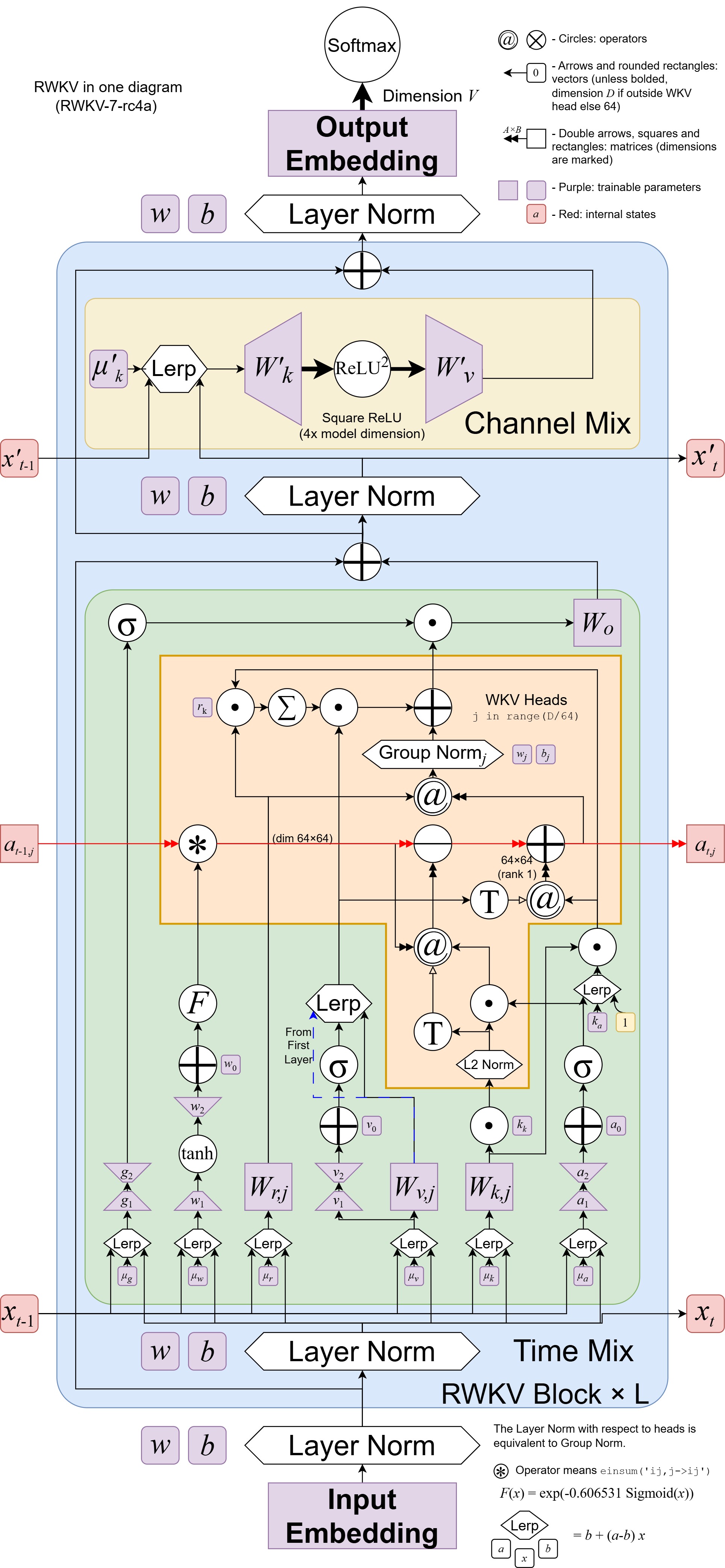
RWKV-7 Architecture Optimization Details
Tips
RWKV-V7 adopts Dynamic State Evolution. Through a series of innovations (such as the Generalized Delta Rule), RWKV-7 comprehensively surpasses the Transformer and the previous RWKV-6 architecture in terms of computational efficiency, task performance, and model expressiveness.
On the premise that the training data is much less than that of open-source models such as Qwen2.5 and Llama3.2, the language modeling ability of the RWKV-7-World model has reached the state-of-the-art (SoTA) level among all open-source models with a scale of 3 billion parameters.
By introducing the Generalized Delta Rule, RWKV-7 can achieve the
In general, traditional attention mechanisms (such as the QKV-softmax-attention of Transformers) store multiple
RWKV-7 does not directly store
Specifically, the RWKV-7 model has an internal model
To achieve this goal, RWKV-7 automatically simulates dynamic gradient descent for the L2 loss function
Gradient formula for state:
State gradient descent formula with weight decay
Equivalent to:
Generalized formula for RWKV-7:
Where reasonable initial values are chosen as:
Comparison of time step formulas and state update mechanisms between RWKV-7 and historical versions (RWKV5/6):
| Model Version | Time Step Formula | State Update Mechanism |
|---|---|---|
| RWKV-5 Eagle | Trainable State Decay | |
| RWKV-6 Finch | Dynamic State Decay | |
| RWKV-7 Goose | Dynamic State Evolution |
Core Mechanism Code
def ref_fwd(r, w, k, v, a, b):
r = r.view(B, T, H, N)
k = k.view(B, T, H, N)
v = v.view(B, T, H, N)
a = a.view(B, T, H, N)
b = b.view(B, T, H, N)
w = torch.exp(-torch.exp(w.view(B, T, H, N)))
out = torch.zeros((B, T, H, N), device=DEVICE)
state = torch.zeros((B, H, N, N), device=DEVICE)
for t in range(T):
kk = k[:, t, :]
rr = r[:, t, :]
vv = v[:, t, :]
aa = a[:, t, :]
bb = b[:, t, :]
sab = torch.einsum('bhik,bhk,bhj->bhij', state, aa, bb)
state = state * w[: , t, :, None, :] + sab + torch.einsum('bhj,bhi->bhij', kk, vv)
out[:, t, :] = torch.einsum('bhj,bhij->bhi', rr, state)
return out.view((B, T, C))
RWKV Architecture Features
The characteristics of the RWKV large model architecture include:
- Efficient and stable inference speed
- Low and fixed memory usage (supports running on CPU)
- Capable of handling infinite context, very suitable for long text processing and multi-round dialogue applications
- Hardware-friendly, only performs matrix and vector multiplication operations, no KV cache
The RWKV architecture consists of a series of stacked residual blocks, each of which consists of time-mixing and channel-mixing sub-blocks with a recurrent structure, which is achieved by linear interpolation between the current input and the last input (in the RWKV-4 architecture paper, this process is called token shift). RWKV 6 optimized the token shift process by borrowing LoRA technology, making the simple linear interpolation (lerp) of RWKV4/5 into a data-dependent, dynamic linear interpolation (ddlerp).
According to the comparison of the inference complexity of different models, the time complexity of Transformer is: O (T^2), and the space complexity is: O (T^2), so the inference speed will become slower and slower, and the memory consumption will also increase. The time complexity of RWKV is: O(T), and the space complexity is O(1). The RWKV large model achieves constant inference speed through the optimization of the calculation process, greatly reducing the time consumption during inference.
In addition, the RWKV architecture design significantly reduces memory usage, making the model efficient on standard configuration CPUs or non-professional GPUs rather than expensive or high-end computing hardware. This breakthrough progress makes large-scale deep learning models no longer limited to specific hardware platforms, thus broadening the application range.
RWKV-V7 Model Release[#rwkv-v7-model-release]
RWKV-V7 has released three series of pre-trained models: Pile, World, and G1.
- RWKV-7-Pile represents experimental models pre-trained on the EleutherAI/pile dataset
- RWKV-7 "Goose" World models are multilingual pre-trained models based on the World V3 dataset and its sampled subsets
- RWKV7-G1 ("GooseOne") series are reasoning models that continue training the RWKV-7 "Goose" World series models on the World v3.5 dataset
The RWKV7-G1 series models are trained on the latest World v3.5 dataset, featuring strong reasoning, coding, and mathematical capabilities.
| Model Name | Model Description |
|---|---|
| rwkv7-g1-0.1b | Trained on 1T tokens randomly sampled from the World v3.5 dataset |
| rwkv7-g1-0.4b | Trained on 2T tokens randomly sampled from the World v3.5 dataset |
| rwkv7-g1-1.5b | Trained on 5T tokens randomly sampled from the World v3.5 dataset |
| rwkv7-g1-2.9b | Trained on 10T tokens randomly sampled from the World v3.5 dataset |
All RWKV7-G1 series models can be viewed at the RWKV7-G1 model repository.
Tips
The World v3.5 dataset is an expanded version of the World V3 dataset, containing additional novels, web pages, mathematics, code, and reasoning data, totaling 5.16T tokens.
RWKV-7-World models are pre-trained on the World V3 dataset and its sampled subsets, available in four parameter sizes: 0.1B/0.4B/1.5B/2.9B.
| Model Category | Model Description |
|---|---|
| RWKV-7-World-0.1B-v2.8 | Multilingual pre-trained model based on the World-v2.8 dataset, available only in 0.1B parameter version |
| RWKV-7-World-0.4B-v2.9 | Multilingual pre-trained model based on the World-v2.9 dataset, available only in 0.4B parameter version |
| RWKV-7-World-1.5B/2.9B-v3 | Pre-trained models based on the complete World V3 dataset, available in 1.5B and 2.9B parameter versions |
All RWKV-7-World series models can be viewed at the RWKV-7-World model repository.
Tips
World-v2.8 dataset: 1T tokens sampled from the World v3 dataset as training data
World-v2.9 dataset: 2T tokens sampled from the World v3 dataset as training data
RWKV-7-Pile models are experimental models based on the Pile dataset, featuring various layer counts and dimensional designs:
- RWKV-x070-Pile-1.47B
- RWKV-x070-Pile-164M-L33-D512
- RWKV-x070-Pile-165M-L25-D576
- RWKV-x070-Pile-168M
- RWKV-x070-Pile-421M
All RWKV-7-Pile series models can be viewed at the RWKV-7-Pile model repository.
RWKV-V8
RWKV-V8's architecture codename is "Heron." RWKV-V8's first feature DeepEmbed was announced in May 2025. DeepEmbed can achieve excellent reasoning performance similar to MoE without consuming VRAM or even RAM, enabling truly sparse large models to be deployed on all edge devices.
RWKV-V8's DeepEmbed
DeepEmbed trains a learnable high-dimensional vector for each token in the vocabulary within the FFN of every model layer, which can be written as an Embed layer. These vectors can be learned during training and stored in RAM/SSD during inference, requiring only minimal parameter prefetching for each token, thus significantly reducing VRAM usage.
During inference, the model can prefetch the embedding vectors for the current layer based on the token index, which are used for channelwise multiplicative modulation (channelwise scaling) of the FFN output.
These token-based embedding vectors form a massive but sparse knowledge base that significantly enhances the model's ability to store and retrieve world knowledge. Although these vectors seemingly increase the model's parameter count, they do not require VRAM, and during training, they can avoid gradient synchronization bandwidth overhead in DP (Data Parallelism) through TP (Tensor Parallelism), and can be further offloaded to RAM or SSD.
In edge inference scenarios, these vectors can likewise be stored in memory or loaded on-demand directly from disk through mechanisms like mmap. Each token introduces only tens of KB of additional memory access overhead, making this mechanism highly suitable for deployment on edge devices.
DeepEmbed Code Examples:
Original ReLuSq FFN:
x = torch.relu(self.key(x)) ** 2
return self.value(x)
DeepEmbed_1x ReLuSq FFN:
self.deepemb = nn.Embedding(d_vocab, d_emb)
...
x = torch.relu(self.key(x)) ** 2
return self.value(x) * self.deepemb(idx)
DeepEmbed_4x ReLuSq FFN (better performance, more parameters):
self.deepemb = nn.Embedding(d_vocab, d_emb * 4)
...
x = torch.relu(self.key(x)) ** 2
return self.value(x * self.deepemb(idx))
Tips
Since lookup operations do not consume VRAM during inference, these vectors are essentially "free" in terms of parameter count. Therefore, n-grams (such as bigram, trigram) can be further introduced to enhance the model's ability to model phrases/segments. If the vocabulary size is large, LoRA techniques can also be combined to reduce VRAM and training overhead.
RWKV Architecture Features
The characteristics of the RWKV large model architecture include:
- Efficient and stable inference speed
- Low and fixed VRAM usage (supports CPU execution)
- Ability to handle infinite context, making it ideal for long text processing and multi-turn conversations
- Hardware-friendly design, performing only matrix-vector multiplications without requiring KV cache
The RWKV architecture consists of a series of stacked residual blocks, each composed of time-mixing and channel-mixing sub-blocks with recurrent structures. This recurrence is achieved through linear interpolation between the current input and the input from the previous time step (referred to as token shift in the RWKV-4 architecture paper). RWKV-6 optimizes the token shift process by borrowing from LoRA techniques, transforming the simple linear interpolation (lerp) of RWKV-4/5 into data-dependent, dynamic linear interpolation (ddlerp).
Comparing inference complexity across different models, Transformers have time complexity of O(T²) and space complexity of O(T²), resulting in increasingly slower inference and higher memory consumption. In contrast, RWKV has time complexity of O(T) and space complexity of O(1). Through computational flow optimization, RWKV large models achieve constant inference speed, dramatically reducing time consumption during inference.
Furthermore, the RWKV architecture design significantly reduces VRAM usage, enabling efficient model operation even on standard CPU configurations or non-professional GPUs, without dependence on expensive or high-end computing hardware. This breakthrough advancement removes the hardware platform constraints on large-scale deep learning models, broadening their application scope.
RWKV Architecture References
For core concepts of the RWKV architecture, please refer to RWKV in 150 lines of code.
For the architectural design of RWKV-7, you can refer to the blog: RWKV-7 as a meta-context learner.
Alternatively, you can learn by reading RWKV papers:
- RWKV-4 Architecture Paper | arXiv (2305.13048)
- RWKV 5/6 Architecture Paper | arXiv (2404.05892)
- RWKV-7 Architecture Paper | arXiv(2503.14456)
If you have mastered the basics, you can start studying the training and CUDA code of RWKV in the RWKV main repository.
Overview paper on the development of the RWKV architecture: Overview of the Development of the RWKV Architecture | arXiv (2411.02795)
A collection of papers and resources related to a survey of RWKV: A Survey of RWKV | arXiv (2412.14847)